Kylin的使用
# 核心概念
数据仓库、OLAP与OLTP、维度和度量、事实表和维度表、星型模型与雪花模型
# 数据仓库
这是商业智能(BI)的核心部分,主要是将**不同数据源的数据整合到一起**,通过多维分析为企业提供决策支持、报表生成等。存入数据仓库的资料必定包含时间属性。
数据仓库与数据库的主要区别:用途不同。
|数据库|数据仓库|
|-|-|
|面向事务|面向分析|
|存储在线的业务数据,对上层业务改变作出实时反映,遵循三范式设计。|历史数据,主要为企业决策提供支持,数据可能存在大冗余,但是利于多个维度查询,为决策者提供更多观察视角。|
一般来说,在传统BI领域里,数据仓库的数据同样是存储在MySQL这样的数据库中。大数据领域最常用的数据仓库就是Hive,我们要学习的Kylin也是以Hive作为默认的数据源的。
数仓分层
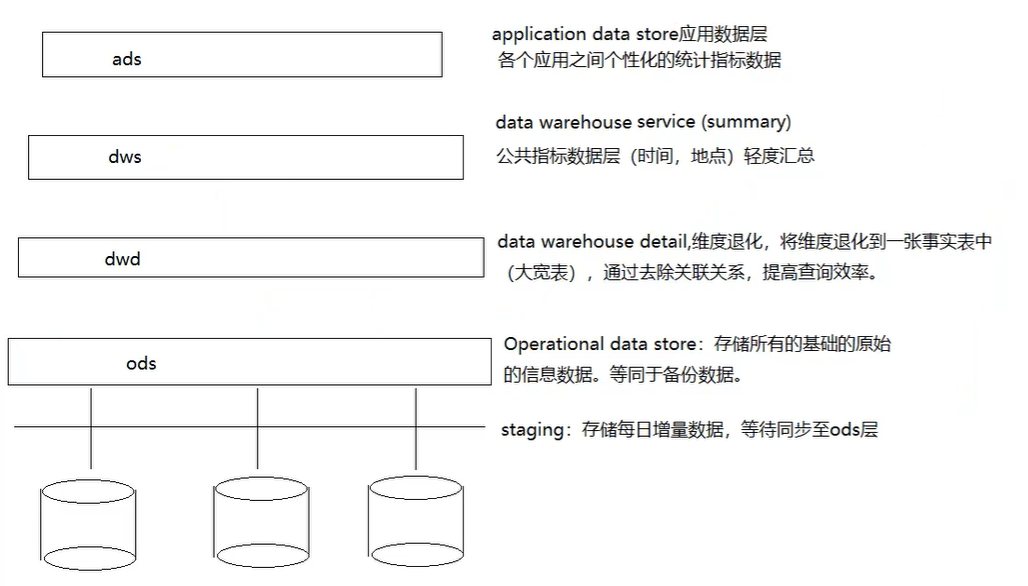
为什么分层?
复杂问题简单化、隔离原始数据(后期统计和真实数据解耦)、数据复用性提高
# OLAP与OLTP
OLAP,联机分析处理,大历史数据为基础,配合时间点的差异,以多维度的方式分析数据,一般带有主观的查询需求,多应用在数据仓库。
OLTP,联机事务处理,侧重于数据库的增删查改等常用业务操作。
对于OLAP系统(数据仓库)就是我们在统计的时候将维度相同的记录聚合在-起,然后应用聚合函数做各种各样
的聚合计算。看一下年度销售额是否在正常范围,和往年的同比增幅,都可以一目了然。
# 维度和度量
这两个是数据分析领域中两个常用的概念。维度( Dimension)简单来说就是你观察数据的角度,也就是数据记录的一个属性例如时间、地点等。度星( Measure)就是基于数据所计算出来的考量值,通常就是一个数据比如总销售额,不同的用户数量。我们就是从不同的维度来审查度星值,以便我们分析找出其中的变化规律。对应我们的SQL查询,group by 的属性通常就是我们考量的维度,所计算出来的比如sum (字段) 就是我们需要的度量。
# 立方体Cube 和 物化视图cuboid
我们在确定好了维度和度量之后,我们根据定义好的维度和度量,就可以构建cube (立方体) 。也就是所谓的预计算,对原始数据建立的多维度索引。
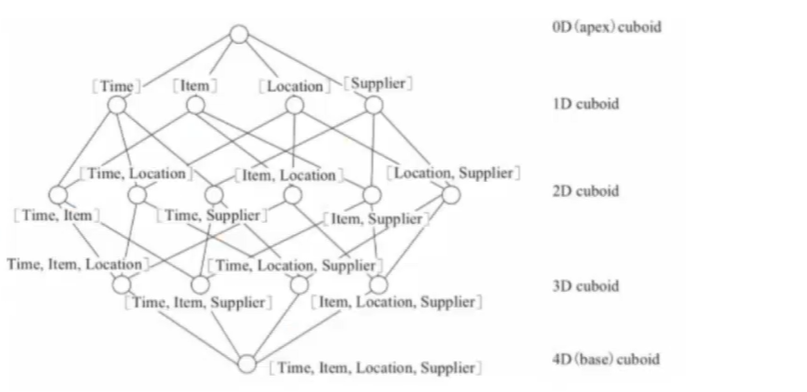
给定一个数据模型,我们可以对其上的所有维度进行组合。对于N个维度来说,组合的所有可能性共有2^N种。对于每一种维度的组合,将度量做聚合运算,然后将运算的结果保存为一个物化视图,称为Cuboid.所有维度组合的Cuboid作为-个整体,被称为Cube.所以简单来说,一个Cube就是许多按维度聚合的物化视图的集合。下面来列举一个具体的例子。假定有一个电商的销售数据集,其中维度包括时间(Time)、商品(Item)、地点(Location)和供应商( Supplier)。度量为销售额(GMV)。那么所有维度的组合就有2^4 =16 即16种(如下图所示) .比如一维度( 1D)的组合有[Time]、[Item]、 [Location]、 [Supplier] 4种;二维度(2D)的组合有[Time, Item]、 [Time,Location]、[Time、 Supplier]、 [Item, Location]、 [Item, Supplier]. [Location, Supplier] 6种;三维度(3D)的组合也有4种;最后零维度(0D)和四维度( 4D)的组合各有1种,总共就有16种组合。下图为kylin官方图例。
# Cube Segment
见名知意代表的是元数据中的某一个片段计算出的 cube数据。通常数据仓库中的数据最会随着时间的增长而增长,而Cube Segment 也是按照时间顺序来构建的。
# 事实表、维度表
实表(Fact Table) 是指存储有事实记录的表,如系统日志销售记录等;实表的记录在不断地动态增长,所以它的体积通常远大于其他表。
维度表(Dimension Table) 或维表,有时也称查找表( Lookup Table) ,是与事实表相对应的一种表;它保存了维度的属性值,可以跟事实表做关联;相当于将事实表上经常重复出现的属性抽取、规范出来用一张表进
行管理。
常见的维度表有:日期表(存储与日期对应的周、月、季度等的属性)、地点表 (包含国家、省/州、城市等属性)等。使用维度表有诸多好处,具体如下:
●缩小了事实表的大小。
●便于维度的管理和维护,增加、删除和修改维度的属性,不必对事实表的大量记录进行改动。
●维度表可以为多个事实表重用,以减少重复工作。
# 多维数据模型
## 星型模型
星型模型就是一张事实表,以及零个或多个维度表;实表与维度表通过主键外键相关联,维度表之间没有关联,就像很多星星围绕在一个恒星周围,故取名为星形模型。
## 雪花模型
将星形模型中的某些维表抽取成更细粒度的维表,然后让维表之间也进行关联,这种形状酷似雪花的的模型称为雪花模型。
二者区别:
星型模型因为数据的冗余所以很多统计查询不需要做外部的连接,因此一般情况下效率比雪花型模型要高。星型结构不用考虑很多正规化的因素,设计与实现都比较简单。
雪花型模型由于去除了冗余,有些统计就需要通过表的联接才能产性,所以效率不-定有星型模型高。正规化也是一种比较复杂的过程,相应的数据库结构设计、数据的ETL.以吸后期的维护都要复杂一些。 因此在兄余可以接受的前提下,实际运用中星型模型使用更多,也更有效率。
| |星型模型|雪花模型|
|-|-|-|
|数据总量|多|少|
|可阅读性|相对容易|相对差|
|表的个数|少|多|
|查询效率|快|慢|
|冗余度|高|低|
|可扩展性|差|好|
# Kylin由来
Apache Kylin (Extreme OLAP Engine for Big Data)是-个开源的分布式分析引擎,为Hadoop等大型分布式数据平台之上的超大规模数据集通过标准SQL 查询及多维分析(OLAP )功能,提供亚秒级的交互式分析能力。
Apache Kylin, 中文名麒麟,是Hadoop动物园中的重要成员。Apache Kylin 是一个开源的分布式分析引擎,最初由eBay开发贡献至开源社区。它提供Hadoop之上的SQL查询接口及多维分析(OLAP )能力以支持大规模数据,能够处理TB乃至PB级别的分析任务,能够在亚秒级查询巨大的Hive表,并支持高并发。
Apache Kylin 于2014年10月在github开源,并很快在2014年11月加入Apache孵化器,于2015年11月正式毕业成为Apache顶级项目,也成为首个完全由中国团队设计开发的Apache 顶级项目。于2016年3月,ApacheKylin核心开发成员创建了Kyligence公司,力求更好地推动项目和社区的快速发展。
为什么使用它
在大数据的背景下,Hadoop 的出现解决了数据存储问题,但如何对海星数据进行LAP查询,却一直令人十分头疼。企业中大数据查询大致分为两种:即席查询和定制查询。
●即席查询
Hive、SparkSQL 等OLAP引擎,虽然在很大程度上降低了数据分析的难度,但它们都只适用于即席查询的场景。它们的优点是查询灵活,但是随着数据量和计算复杂度的增长,响应时间不能得到保证。
●定制查询
多数情况下是对用户的操作做出实时反应,Hive 等查询引擎很难满足实时查询,一般只能对数据仓库中的数据进
行提前计算,然后将结果存入Mysql等关系型数据库,最后提供给用户进行查询。
在上述背景下,Apache Kylin 应运而生。不同于大规模并行处理Hive等架构,Apache Kylin 采用“预计算”的模式,用户只需要提前定义好查询维度,Kylin 将帮助我们进行计算,并将结果存储到HBase中,为海量数据的查询和分析提供亚秒级返回,是-种典型的空间换时间的解决方案。
Apache Kylin 的出现不仅很好地解决了海量数据快速查询的问题,也避免了手动开发和维护提前计算程序带来的一系列麻烦。
# 业务流程:
大宽表:(维度退化:定义维度和度量关系)创建临时Hive平表(从Hive读取数据)
重分布、抽维度(需要去重):满足分布式的特点,计算不同维度的不同值,开始收集Cuboid的统计数据
造字典:创建并保存字典
度量值的产生(Cuboid):保存Cuboid统计信息。SQL要算什么
创建HTable:往哪存
计算Cube:build:base、0-N、1-N、2-N(维度组合构建)(一轮或多轮MapReduce)
数据迁移:将Cube的计算结果转成HFile,再加载HFile到HBase:build——>data——connect——>HFile——load——>HBase
更新Cube元数据
垃圾回收cube:Hive、HBase操作过程中的临时文件(目录)的清理
# 查询注意事项
1、只能按照构建model的连接条件来写sql
在创建model的时候使用的是inner join内连接,在使用kylin查询的时候只能使用join内连接,其他会报错,并且在写查询语句的时候是事实表在前维度表在后,否则还是会报错
2、只能按照构建cube时选择的维度字段分组统计
# Kylin查询API:
之前我们成功创建了kylin的cube,并且可以使用web ui 查询.但除了通过web i 进行操作,我们还可以使用api调用。
RestFul API
在使用之前,我们要先进行认证,目前Kylin使用basic Authentication. Basic Authentication是一种非常简单的访问控制机制,它先对账号密码基于Base64编码,然后将其作为请求头添加到HTTP请求头中,后端会读取请求头中的账号密码信息以进行认证。
以Kylin默认的账号密码ADMIN/ KYLIN为例,对相应的账号密码进行编码后,结果为Basic QURNSU46S1MSU4=,那么HTTP对应的头信息则为Authorization:Basic QURNSU46S1 lMSU4=。
查询SQL
```
curl -X POST -H "Authorization: Basic QURNSU46S11MSU4=" -H 'Content-Type:application/json' http://localhost:7070/kylin/api/query -d '{
"sq1":"select market, sum(sales) from kylin_sale group by market",
"offset":0,
"limit":10,
"acceptPartial":false,
"project":"my_kylin"
}'
```
参数解释:
●sql:必填,宇符串类型,请求的SQL。
●offset: 可选,整型,查询默认从第一行返回结果,可以设置该参数以决定返回数据从哪一行开始往后返回。
●limit: 可选,整型,加上limit参数后会从offset开始返回对应的行数,返回数据行数小于limit的将以实际行数为准。
●acceptPartial: 可选,布尔类型,默认是true. 如果为true.那么实际上最多会返回一百万行数据;如果要返回的结果集超过了一百万行.那么该参数需要设置为false。
●project: 可选,字符串类型,默认为DEFAULT ,在实际使用时,如果对应查询的项目不是DEFAULT,那就需要设置为自己的项目。
# Put提交cube
```language
curl -X PUT -H "Authorization: Basic QURNSU46S1MSU4=" -H 'Content-Type: application/json'
http://localhost:7070/kylin/api/cubes/my_cube/build -d '{
"startTime":0,
"endTime":"SendTime",
"buildType":"BUILD",
}'
```
上面的内容里面,url 里面的my. cube是你自己的cube名,endTime 是你需要去指定的,startTime :当cube中不存在segment时,可以将其设置为0,那么就会从头开始算。做增量时,startTime 要设置为.上一次build的endTime。endTime :时间精确到毫秒(例138856300000buildType :可选BUTUD.MERGE.REFRESH.
# 注意点
我们在通过RESTful API 向kylin进行build和rebuild的时候一定要观察kylin的web界面下面的Montior进程,否则一不小心运行太多进程导致服务器崩掉。
我们可以通过
```shell
curl -x GET -H "Authorization: Basic xxxxxxx=” -H‘Content-Type: application/json http://localhost:7070/kylin/api/jobs/ {job._uuid}
```
来跟踪任务状态返回的job_status 代表job的当前状态。Uuid是cube提交build时返回的json格式数据中
获得。形如: 7da54847-ce51-1e43-156a-a9c92a7123e0。
如果构建过程中出现错误,执行如下进行任务的重新执行。指定对应uuid的任务。
```curl -X PUT -H "Authorization: Basic xxxxxxx=" -H "Content-Type: application/json" http://localhost:7070/kylin/api/jobs/{job.uuid}/resume
```
# 增量Cube
Cube划分为多个Segment,每个Segment用起始时间和结束时间来标志。Segment 代表一段时间内源数据的预计算结果。在大部分情况下一个Segment的起始时间等于它之前那个Segment的结束时间,同理,它的结束时间等于它后面那个Segment的起始时间。
同一个Cube下不同的Segment除了背后的源数据不同之外,其他如结构定义、构建过程、优化方法、存储方式等都完全相同。
## 为什么要增量构建
在全量构建中,存在唯一的一个Segment,该Segment没有分割时间的概念,因此也就没有起始时间和结束时间。全星构建和增星构建各有其适用的场景,用户可以根据自己的业务场景灵活地进行切换。全星构建和增星构建的详细对比如下表:
|全量构建|增量构建|
|-|-|
|每次更新时都需要更新整个数据集|每次只对需要更新的时间范围进行更新,因此离线计算量相对较小|
|查询时不需要合并不同Segment的结果|查询时需要合并不同Segment的结果,因此查询性能会受到影响|
|不需要后续的Segment合并|累计一定量的Segment之后,需要进行合并|
|适合小数据量或全表更新的Cube|适合大数据量的Cube|
对于全量构建来说,每当需要更新Cube数据的时候,它不会区分历史数据和新加入的数据,也就是说,在构建的时候会导入并处理所有的原始数据。而增星构建只会导入新Segment指定的时间区间内的原始数据,并只对这部分原始数据进行预计算。
注:增量和全量的区别,最基础就看模型有没有选择时间分区,若是全量每次都是计算全部,工作量比较大
## 设计增量构建的前提
并非所有的Cube都适用于增量构建,Cube 的定义必须包含一个时间维度,用来分割不同的Segment,我们将这样的维度称为分割时间列( Partition Date Column) 。分割时间列既可以是Hive中的Date类型、也可以是Timestamp类型或String类型。无论是哪种类型,Kylin 都要求用户显式地指定分割时间列的数据格式,例如精确到年月日的Date类型(或者String类型)的数据格式可能是yyyMMdd或yY-MM-dd,如果是精确到时分秒的Timestamp类型(或者String类型),那么数据格式可能是YYYY-MM-DD HH:MM:SS。
## 触发增量构建
在Web UI上触发Cube的增量构建与触发全量构建的方式基本相同。在Web UI 的Model页面中,选中想要增量构建的Cube,单击Action→Build。
不同于全星构建,增星构建的Cube会在此时弹出对话框让用户选择End Date。Kylin 要求增星Segment的起始时间等于Cube 中最后一个Segment的结束时间,因此当我们为一个已经有Segment的Cube触发增量构建的时候,Start Date 的值已经被确定,且不能修改。
仅当Cube中不存在任何Segment。或者不存在任何未完成的构建任务时,Kylin 才接受该Cube.上新的构建任务。
而如果不是web GUI 触发,你通过restAPI触发的话,那么要确保你给定的时间,不重给。
## 自动合并
在Cube Designer 的Refresh Settings 的页面中有Auto Merge Thresholds 和Retention Threshold两个设置项可以用来帮助管理Segment碎片。
Auto Merge Thresholds 允许用户设置几个层级的时间阈值,层级越靠后,时间阈值就越大。举例来说,用户可以为一个Cube指定(天28天)这样的层级。每当Cube中有新的Segment状态变为READY的时候,就会触发-次系统试图自动合并的尝试。系统首先会尝试最大一级的时间阈值,结合上面的(天28天) 层级的例子,首先查看是否能将连续的若干个Segment合并成为一个超过28天的大Segment,在挑选连续Segment的过程中,如果遇到已经有个别Segment的时间长度本身已经超过了28天,那么系统会跳过该Segment,从它之后的所有Segment中挑选连续的累积超过28天的Segment.如果满足条件的连续Segment还不能够累积超过28天,那么系统会使用下一个层级的时间阈值重复寻找的过程。每当找到了能够满足条件的连续Segment,系统就会触发一次自动合并Segment的构建任务,在构建任务完成之后,新的Segment被设置为READY状态,自动合并的整套尝试又需要重新再来一遍。
## 保留Segment
从碎片管理的角度来说,自动合并是将多个Segment合并为-个Segment,以达到清理碎片的目的。保留Segment则是从另外-个角度帮助实现碎片管理,那就是及时清理不再使用的Segment。
在很多业务场景中,只会对过去- -段时间内的数据进行查询, 例如对于某个只显示过去1年数据的报表,支撑它的Cube事实上只需要保留过去年内的 Segment即可。由于数据在Hive中往往已经存在备份,因此无需再在Kylin中备份超过一年的历史数据。
在这种情况下,我们可以将Retention Threshold 设置为365。每当有新的Segment状态变为READY的时候,系统会检查每-个Segment :如果它的结束时间距离最晚的一个Segment的结束时间已经大于Retention Threshold,那么这个Segment将被视为无需保留。系统会自动地从Cube中删除这个Segment。
如果启用了Auto Merge Thresholds ,那么在使用Retention Threshold 的时候需要注意,不能将Auto Merge Thresholds 的最大层级设置得太高。假设我们将Auto Merge Thresholds 的最大-级设置为1000天,而将Retention Threshold 设置为365天,那么受到自动合并的影响,新加入的Segment会不断地被自动合并到一个越来越大的Segment之中,但是这样会导致kylin要去不断地更新这个大Segment的结束时间,从而导致这个大Segment永远还会得到释放。因此,推荐自动合并的最大一级的时间不要超过1年。
## 数据持续更新
在实际应用场景中,我们常常会遇到这样的问题:由于ETL过程的延迟,业务每天都需要刷新过去N天的Cube数据。
举例来说,客户有一个报表每天都需要更新,但是每天的源数据更新不仅包含了当天的新数据,还包括了过去7天内数据的补充。
一种比较简单的方法是,天在Cube中增量构建一个长度为一天时Segment.这样过去7天的数据就会以7个Segment的形式存在于Cube之中。Cube 的管理员除了每天要创建一个新的 Segment代表当天的新数据(BUILD操作)以外,还需要对代表过去天的7个Segment进行刷新( REFRESH操作,Web UI. 上的操作及Rest API 参数与BUILD类似,这里不再详细展开)。这样的方法固然可以奏效,但是每天为每个Cube触发的构建数量太多,容易造成Kylin的任务队列堆积大量未能完成的任务。
上述简单方案的另外一个弊端是,每天一个Segment也会让Cube中迅速地累积大量的Segment,需要Cube管理员手动地对历史已经超过7天的Segment 进行合并,期间还必须小心地操作,不能错将7天内的Segment一起合并了。
举例来说,假设现在有100个Segment,每个Segment代表过去的一天的数据,Segment 按照起始时间排序。在合并时,我们只能挑选前面93个Segment进行合并,如果不小心把第94个Segment也-起合并了,那么当我们试图刷新过去天(94-100)的Segment的时候,会发现为了刷新第94天的数据,不得不将1~93的数据一并重新计算,这对于刷新来说是一种极大的浪费。而且最差的情况就是即使使用之前所介绍的自动合并的功能,类似的问题也仍然存在。
### 解决思路:
不以日为单位创建新的Segment,而是以N天为单位 创建新的Segment。
举例来说,假设用户每天更新Cube的时候,前面7天的数据都需要更新-下,也就是说,如果今天是01-08,那么用户不仅要添加01-08的新数据,还要同时更新01-01到01-07的数据。在这种情况下,可设置N=7作为最小Segment的长度。在第一天01-01, 创建一个新的Segment A,它的时间是从01-01到01-08, 我们知道Segment是起始时间闭,结束时间开,因此Segment A的真实长度为7天,也就是01-01到01-07。 即使在01-01当天,还没有后面几天的数据,Segment A也能正常地构建,不过构建出来的Segment实只有01-01一天的数据而已。从01-02到01-07的每一天,我们都要刷新Segment A,以保证1日到7日的数据保持更新。由于01-01已经是 最早的日期,所以不需要对更早的数据进行更新。
到01-08的时候,创建一个新的 Segment B.它的时间是从01-08到01-15。此时我们不仅需要构建Segment B,还需要去刷新Segment A。因为01-01到01-07中的数据在01-08当天仍然可能处于更新状态。在接下来的01-09到01-14,每天刷新A. B两个Segment.等到了01-15这天的时候,首先创建一个新的Segment C,它的时间是从01-15到01-22。在01-15当天,Segment A的数据应当已经被视作最终状态,因为Segment A中的最后一天(01-07) 已经不再过去N天的范围之内了。因此此时接下来只需要照顾Segment B和Segment C即可。
由此可以看到,在任意-天内, 我们只需要同时照顾两个Segment.第一个Segment主要以刷新近期数据为主,第二个Segment则兼顾了加入新数据与刷新近期数据。这个过程中可能存在少量的多计算,但是每天多余计算的数据量不会超过N天的数据量。这对于Kylin整体的计算量来说是可以接受的。根据业务场景的不同,N可能是天,也有可能是30天,我们可以适度地把最小的Segment设置成比N稍微大一点的数字。
# cuboid以及cube优化
按照dimension大小顺序排序,从Base Cuboid 开始,依次基于上一层Cuboid的结果进行再聚合。每一层的计算都是一个单独的Map Reduce (Spark) 任务。
理论上来说,一个N维的Cube,便有2的N次方种维度组合,参考kylin官网上的一个例子, 一个Cube包含time,item, location, supplier 四个维度,那么组合( Cuboid)便有16种。
一个Cube中,当维度数量N超过一定数量后,空间以及计算消耗将会非常大,比如说10维那就是1024个cuboid,但我们真正查询的时候可能只会用到其中的100个cuboid,如果不做优化那么会出现以下几个问题
●会使得Build出来的Cube Size 很大,从而占用大量的磁盘空间;
●Cube Building的时间会很长;
●会占用集群的计算资源。
## Cube剪枝优化
### 聚合组Aggravation Group
Kylin在定义Cube时候,可以将维度拆分成多个聚合组( Aggregation Groups )这也就是我们在web页面创建cube时的第5步可以做,只在组内计算Cube,聚合组内查询效率高,跨组查询效率较差,所以需要根据业务场景,将常用的维度组合定义到一个聚合组中,提高查询性能,这也是Kylin中查询性能优化的一个重要方面。
举例:
业务场景有4个维度,分别为ABCD. 如果聚合组含有的维度为ABCD的话,它的Cuboid为2^4=16个。 但是此时如果AB是一个聚合组, CD是一个聚合组, 那么Cuboid的个数就是2*2+2^2=8个, 相当于缩减了一半。即原来2^(K+M+N)个Cuboid可以减少到2^K+2^M+2^N个。查看cube所生成的cuboid个数命令如下:
`kylin.shorg.apache.kylin.engine.mr.common.CubeStatsReader CubeName`
#### 强制维度( Mandatory Dimensions )
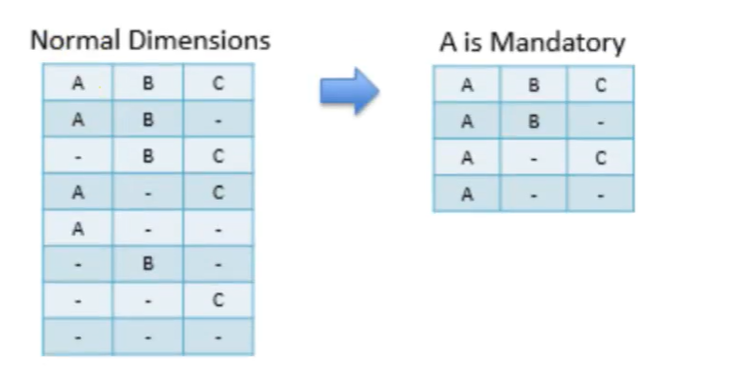
如果一个维度被定义为强制维度,那么这个分组产生的所有Cuboid中每一个Cuboid都会包含该维度。如果根据这个分组的业务逻辑,相关的查询一定会在过滤条件或分组条件中,则可以在该分组中把该维度设置为强制维度。
#### 层次维度( Hierarchy Dimensions )
何为层次维度,具有上下级层次关系的维度,例如时间维度年->月->日,和地区维度国家(country)->省份(province)->城市(city) 。将有这样关系的维度设置为层次关系,并且将它们设置为层次维度的话,cuboid数量将下降。
举例:
如果有三个维度A,B, C设置为层次维度,那么Cuboid数量将由2^3减为3+1 (ABC、AB、A.空)。

对应的group by就变成了如下三种情况
group by country, province, city (等同于group by country, city 或者group by city )
group by country, province (等同于 group by province )
group by country 。
Hive里面的数据以时间作为分区,每天处理增量数据,那么我们kylin也要每天增量写入数据。
#### 联合维度(Joint Dimensions)
每个联合中包含两个或更多个维度,如果某些列形成一个联合, 那么在该分组产生的任何Cuboid中,这些联合维度要么一起出现,要么都不出现。如果根据这个分组的业务逻辑,多个维度在查询中总是同时出现,则可以在该分组中把这些维度设置为联合维度。
例子:如有ABCD四个维度,B C维度作为联合维度,则最后只要生成7个维度,如下图所示:其中红色维度为无需生成的维度,黑色维度为需要生成的维度

### 衍生维度
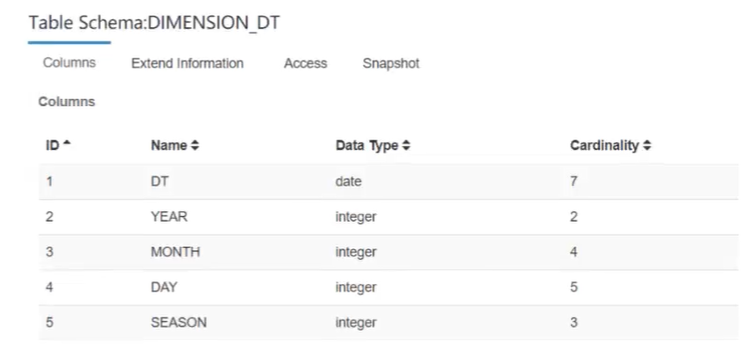
时间维度表,里面充所着用途各异的时间维度,例如每个日期所处的季度、月份等。这些维度可以被地用来进行各个时间粒度上的聚合分析,而不需要进行额外的上卷(Roll Up)操作。但是为了这个目的一下子引入这么多个维度,导致Cube中总共的Cuboid数量呈现爆炸式的增长往往是得不偿失的。
当用户需要以更高的粒度(比如按周、按月)来聚合时,如果在查询时获取按日聚合的Cuboid数据,并在查询引擎中实时地进行上卷操作,那么就达到了使用牺牲一部分运行时性能来节省Cube空间占用的目的。
Kylin将这样的理念包装成为了一个简单的优化工具——衍生维度。
衍生维度用于在有效维度内将维度表上的非主键维度排除掉,并使用维度表的主键(实是事实表上相应的外键)来替代它们。Kylin 会在底层记录维度表主键与维度表其他维度之间的映射关系,以便在查询时能够动态地将维度表的主键翻译成这些非主键维度,并进行实时聚合。
例如,假设有一个日期查找表,其中的cal dt是主键列,还有许多派生列,例如week_ begin. dt,mont9h_ begin_ dt.即使分析人员需要week. begin. dt作为维度,我们也可以对其进行修剪,因为它始终可以从cal_dt维度进行计算,这是“派生”优化。
只会计算事实表中的正常维度的组合数据,因为事实表中的颗粒度暂时认为是最细粒度的结果,可以通过上卷切出更粗粒度的结果。(减少存储,牺牲掉部分简单计算的查询性能)
# 计算Rowkey编码优化
编码(Encoding)代表了该维度的值应使用何种方式进行编码,合适的编码能够减少维度对空间的占用,例如,我们可以把所有的日期都用三个字节进行编码,相比于字符串存储,或者是使用长整数形式存储的方法,我们的编码方式能够大大减少每行Cube数据的体积。而Cube中可能存在数以亿计的行数,使用编码节约的空间累加起来将是一个非常巨大的数字。
目前Kylin支持的编码方式有以机种:
- Date编码:将日期类型的数据使用三个字节进行编码,支持从000-01-01到9999-01-01中的每一个日期。
- Time编码:仅支持表示从1970-01-01 00: 00: 00到2038-01-19 03: 14: 07的时间,且Time-stamp类型的维度经过编码和反编码之后,会失去毫秒信息,所以说Time编码仅仅支持到秒。但是Time编码的优势是每个维度仅仅使用4个字节,这相比普通的长整数编码节约了一半。如果能够接受秒级的时间精度,请选择Time编码来代表时间的维度。
- Integer编码: Integer编码需要提供一个额外的参数Length来代表需要多少个字节。 Length的长度为1~8。如果用来编码int32类型的整数,可以将Length设为4;如果用来编码int64类型的整数,可以将Length设为8。在更多情况下,如果知道一个整数类型维度的可能值都很小,那么就能使用Length 为2甚至是1的int编码来存储,这将能够有效避免存储空间的浪费。
- Dict编码:对于使用该种编码的维度,每个Segment在构建的时候都会为这个维度所有可能的值创建一个字典,然后使用字典中每个值的编号来编码。Dict 的优势是产生的编码非常紧凑,尤其在维度值的基数较小且长度较大的情况下,特别节约空间。由于产生的字典是在查询时加载入构建引擎和查询引擎的,所以在维度的基数大、长度也大的情况下,容易造成构建引擎或查询引擎的内存溢出。
- Fixed, length编码:编码需要提供一个额外的参数Length来代表需要多少个字节。该编码可以看作Dict编码的一种补充。对于基数大、长度也大的维度来说,使用Dict可能不能正常工作,于是可以采用一段固定长度的字节来存储代表维度值的字节数组,该数组为字符串形式的维度值的UTF-8字节。如果维度值的长度大于预设的Length,那么超出的部分将会被截断。
遇到:
```log
org.apache.kylin.engine.mr.exception.MapReduceException: no counters for job job_1663636064241_0146Job Diagnostics:
Failure task Diagnostics:
Error: Java heap space
```
在linux执行如下代码
```bash
# 排序使用的内存
set io.sort.mb=10;
#设置 set io.sort.mb=10; 默认值是100,问题轻松解决;
#其他几个参数: set hive.map.aggr=true; //在map端做部分聚合
#set hive.groupby.skewindata=true;//解决数据倾斜问题
#io.sort.mb 的作用
#排序所使用的内存数量。
#默认值:100M,需要与mapred.child.java.opts相配 默认:-Xmx200m。
#不能超过mapred.child.java.opt设置,否则会OOM。
```