分布式锁 附录
# 分布式锁
## 配置环境
```xml
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.12.0</version>
</dependency>
<!--不要引入该依赖, 因为该依赖也配置了RedisTemplate, 底层也可能有直接内存溢出异常, 解决起来很麻烦, 因为之间的已经解决了, 所以别用这个-->
```
```xml
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.12.0</version>
</dependency>
```
```java
@Configuration
public class RedissonConfig {
@Autowired
RedisProperties redisProperties; // 因为自动配置类已经在IOC容器创建该组件, 因此直接注入即可, 这里可以复用redis配置
// 非安全协议, 默认使用这个
public static final String UNSAFE_URL_PREFIX = "redis://";
// 安全协议
public static final String SAFE_URL_PREFIX = "rediss://";
@Bean
public RedissonClient redissonClient() {
Config config = new Config();
String address = UNSAFE_URL_PREFIX + redisProperties.getHost() + ":" + redisProperties.getPort(); // redis://192.168.10.131:3679
config.useSingleServer()
.setAddress(address)
.setPassword(redisProperties.getPassword());
return Redisson.create(config);
}
}
```
## 重量级可重入锁的测试
```java
@GetMapping("/hello")
@ResponseBody
public String hello() {
RLock lock = redissonClient.getLock("lock");
lock.lock();
try {Thread.sleep(15000);} catch (InterruptedException e) {e.printStackTrace();}
lock.unlock();
return "hello";
}
```
### 特性
```java
@GetMapping("/hello")
@ResponseBody
public String hello() {
RLock lock = redissonClient.getLock("lock");
lock.lock();
try {Thread.sleep(60000);} catch (InterruptedException e) {e.printStackTrace();}
lock.unlock();
return "hello";
}
```
1. **如果当前线程获取所资源失败, 会进入无限等待状态, 即被阻塞, 底层采取了CAS**
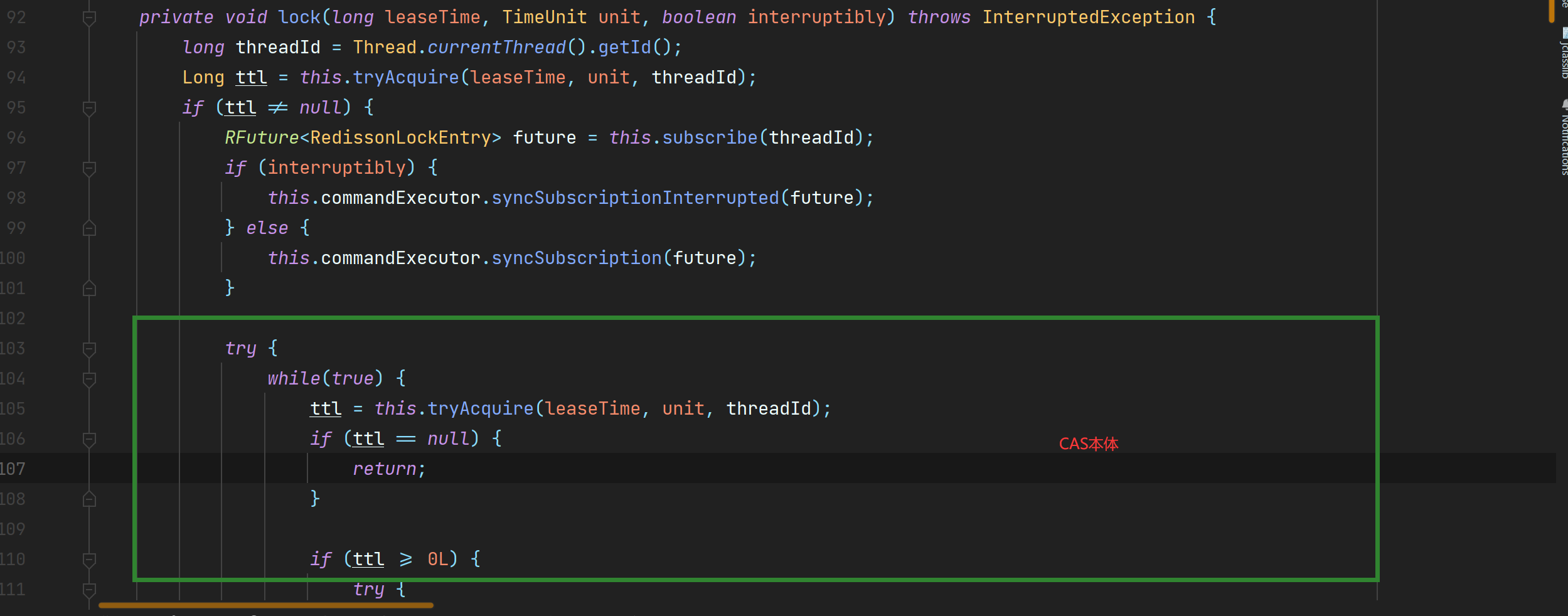
2. **锁资源默认的过期时间是30s, 被称为看门狗时间**, 因此, 即使锁资源释放失败, **也会因为过期时间的耗尽而自动释放锁资源**
3. **锁默认有自动续期的功能**, 如果业务没有完成, 而且看门狗时间消耗了1/3, 会自动续期到一个完整的看门狗时间, 直到完成任务或异常退出, **彻底解决了释放别人锁资源的问题**
4. 锁资源释放后, 不会再自动续期了, 包括宕机或异常退出等(原理在后面)
```java
@GetMapping("/hello")
@ResponseBody
public String hello() {
RLock lock = redissonClient.getLock("lock");
lock.lock(30, TimeUnit.SECONDS);
try {Thread.sleep(32000);} catch (InterruptedException e) {e.printStackTrace();}
lock.unlock();
return "hello";
}
```
```java
java.lang.IllegalMonitorStateException: attempt to unlock lock, not locked by current thread by node id: 6c044827-38f0-4ec4-87fe-9efb097ceaa4 thread-id: 119
```
- 上述异常说明了尝试去释放锁, 但是当前线程没有锁, 原因是<font color="red">**设定了过期时间, 看门狗机制失效, 无法自动续期**</font>
## 看门狗机制的源码
[源码](https://www.processon.com/embed/64cdcb14b9f7806c73e5018e)
### 最佳实践
> **在获取重量级可重入锁的时候, 需要指定过期时间**, 这时候可能会觉得, 指定了过期时间, 看门狗机制失效了, 不能自动续期了, 效果不是变差了?
> ***其实一个事务的执行时间可以大致预估, 只要我们把时间调整略大于预估值即可, 如果实际执行时间超过了很多, 大概就是执行失败了, 而且还能使底层逻辑更简单, 提高效率***
## 读写锁的测试
### 为什么需要读写锁?
> 简单来说, 就是为了保证数据的一致性
> 否则, 当我们读取数据的同时, 别人也在写数据, 我们读取出来的数据和实际存储的数据不一致
### 读写锁是否是单例的?
> <font color="red">**这里的读写锁不是单例的**</font>, 就是说, 如果想要释放锁资源, 必须拿到锁的引用才行, <font color="blue">**和JUC不同**</font>,

### 读写锁的特性
> ***读读共享, 读写互斥, 写写互斥***
```java
@GetMapping("/read")
@ResponseBody
public String read() {
RReadWriteLock rwLock = redissonClient.getReadWriteLock("rwLock");
RLock rLock = rwLock.readLock();
rLock.lock();
System.out.println(new Date() + "读");
try {Thread.sleep(10000);} catch (InterruptedException e) {e.printStackTrace();}
rLock.unlock();
return "read";
}
@GetMapping("/write")
@ResponseBody
public String write() {
RReadWriteLock rwLock = redissonClient.getReadWriteLock("rwLock");
RLock wLock = rwLock.writeLock();
wLock.lock();
System.out.println(new Date() + "写");
try {Thread.sleep(10000);} catch (InterruptedException e) {e.printStackTrace();}
wLock.unlock();
return "read";
}
```
## 信号量的测试
### 信号量的特性
> **信号量本质上来说, 和重量级锁没什么区别, 最大的区别是锁资源由原来的一个变成了多个**
> **分布式锁的信号量需要手动设置, key是锁的名字, value是信号量的个数, 即锁资源的个数**
> 分布式下的信号量需要手动设置KV, 获取信号量本质是`vaLue--`, 而获取信号量本质是`value+=`, **因此, 一直释放信号量很可能让信号量一直变大**, 释放信号量需要做出判断!
### 信号量的测试
```java
@GetMapping("/park")
@ResponseBody
public String park() throws InterruptedException {
RSemaphore park = redissonClient.getSemaphore("park");
park.acquire();
return "park";
}
@GetMapping("/go")
@ResponseBody
public String go() throws InterruptedException {
RSemaphore park = redissonClient.getSemaphore("park");
park.release();
return "go";
}
```
### 信号量的用途
> **限流, 我们可以设置一个合理的信号量来限制并发量**
### `tryAcquire`和`acquire`的区别
```java
@GetMapping("/park")
@ResponseBody
public String park() throws InterruptedException {
RSemaphore park = redissonClient.getSemaphore("park");
if (park.tryAcquire()) {
return "park";
}
return "error";
}
@GetMapping("/go")
@ResponseBody
public String go() throws InterruptedException {
RSemaphore park = redissonClient.getSemaphore("park");
park.release();
return "go";
}
```
> `acquire`: 如果能获取到信号量, 继续执行下去, 如果获取不到, 则进入无限等待状态
> `tryAcquire`: 如果能获取到信号量, 返回true, 如果获取不到, 返回false, 用`true`和`false`来替代了线程状态
### 闭锁测试
#### 闭锁特性
> 闭锁有一个阈值, 当这个阈值不为0时, 调用了`await()`方法的线程会进入无限等待状态, 直到阈值变成0, 才能重新进入运行状态, 阈值的减少需要调用`countDown()`方法, 该方法不会阻塞线程
#### 闭锁测试
```java
@GetMapping("/dec")
@ResponseBody
public String dec() {
RCountDownLatch cdl = redissonClient.getCountDownLatch("cdl");
cdl.countDown();
return "dec";
}
@GetMapping("/beg")
@ResponseBody
public String beg() throws InterruptedException {
RCountDownLatch cdl = redissonClient.getCountDownLatch("cdl");
cdl.trySetCount(10);
cdl.await();
return "beg";
}
```
## Redisson的说明
### Redisson的锁为什么都具有原子性?
> **Redisson底层基本上都是用LUA脚本来操作Redis的, 而LUA脚本天生就有原子性, 所以Redisson所有的锁都具有原子性**
### redis规范
#### 锁的规范
1. 一级目录: 作用(LOCK CACHE等)
2. 二级目录: 微服务名称(PRODUCT等)
3. 三级目录: 实现目标(某个功能)
#### 为什么锁需要规范
> 如果创建锁的名字没有特定的规范, 很容易造成多个实现目标之间所用到的锁是同一把锁, 导致锁的粒度变大, 吞吐量贬低
> 即查询A和B都需要获取锁资源, 如果锁资源一样, 查询A会把B锁了, 更形象来说, 你看B站, 看腾信视频的人把你锁了, 很离谱, 因此一定要有规范, 尽量减少锁粒度
#### 锁粒度和吞吐量的关系
> <font color="red">**锁粒度是指同步范围**</font>, 锁粒度越大, 同步范围越大, 并发量越低, 吞吐量越低
## 缓存一致性问题
### 前提
> 如果想要对数据库的数据进行更新操作, 且该数据在缓存中, 遇到这种场景, 就需要考虑缓存一致性问题, 为了解决数据一致性问题, 有两种策略, 分别是<font color="blue">双写策略 和 失效策略</font>
### 双写策略
#### 双写策略是什么?
> **更新数据的场景下, 首先将数据库的数据更新了, 然后同步将缓存中的数据也更新了**
#### 为什么出现缓存一致性问题?
> <font color="red">**本质是上是因为更新数据库和更新缓存并没有原子性, 即更新数据到更新缓存期间, 这一段间隔时间有可能被其他数据更新所干扰, 造成缓存一致性问题**</font>
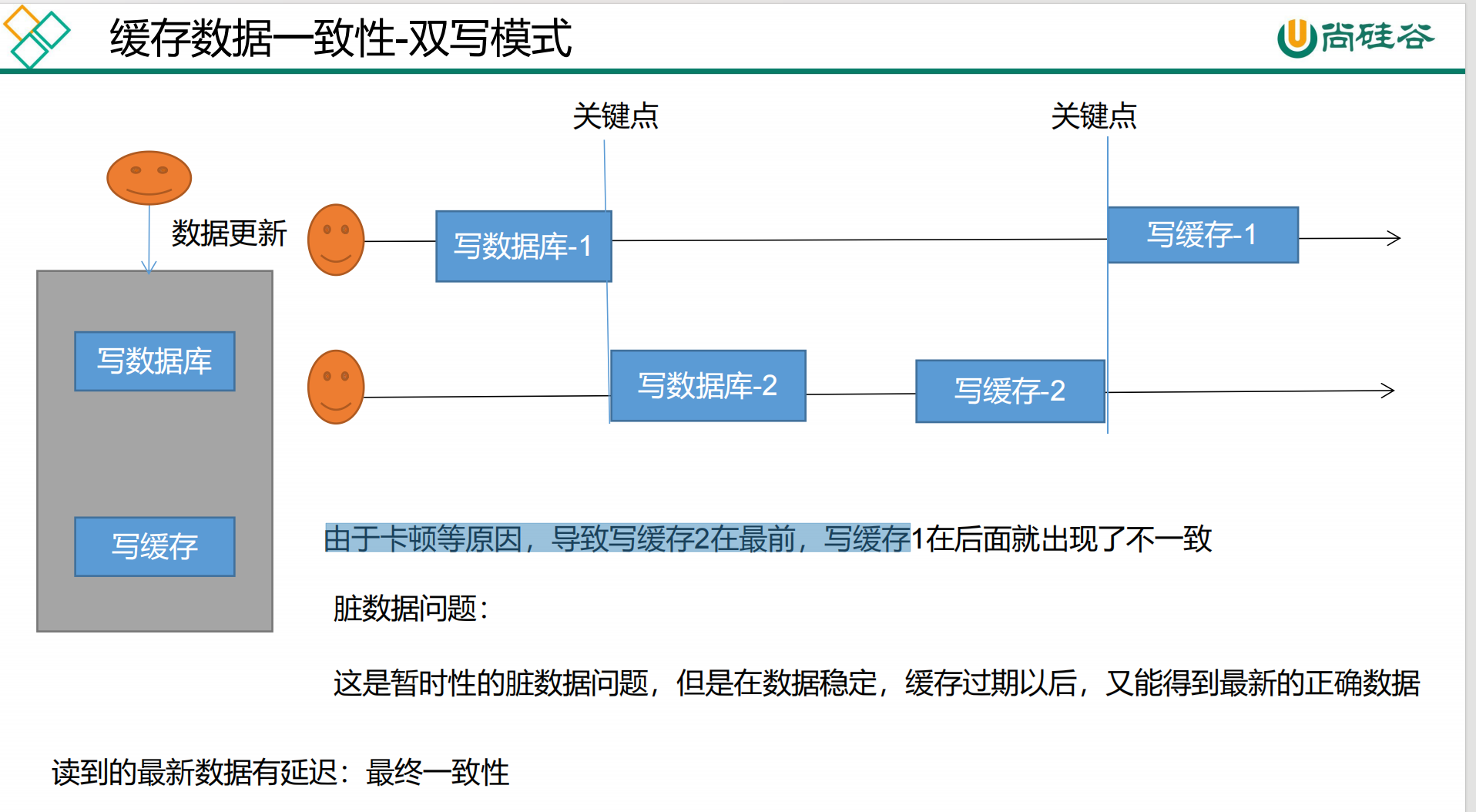
这里并不能保证强一致性(实时一致性), 只能保证最终一致性(只能保证最后数据是一致的, 期间可能不一致)
> 最终一致性是因为有过期时间, 过期时间保证了最终一致性
### 失效策略
#### 失效策略是什么?
> **更新数据的场景下, 首先将数据库的数据更新了, 然后将缓存中的数据删除饿了**
#### 为什么出现缓存一致性问题?
> <font color="red">**本质上是因为整个读操作(读取数据库并更新缓存)没有原子性, 整个写操作(更新数据库和删除缓存)没有原子性**</font>, 因为没有原子性, 很容易被别人趁虚而入
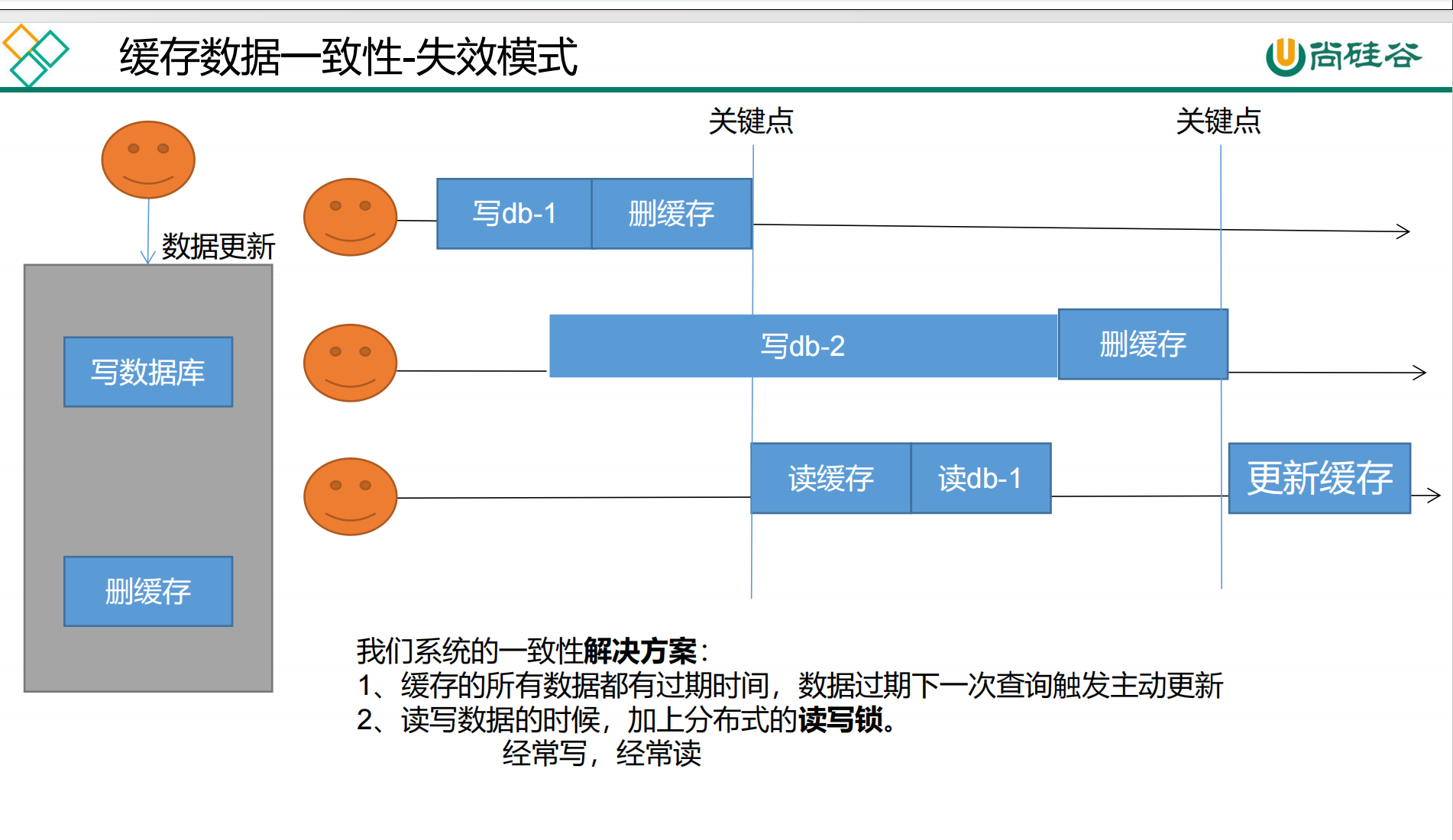
上面是因为读操作的原子性被破坏才会导致的缓存一致性问题
### 如何解决缓存一致性问题
1. 加上读写锁, 根据读写锁的特性可以保证失效策略读写的原子性, 彻底解决缓存一致性问题
2. 加上过期时间, 保证了缓存最终一致性
### canal的介绍
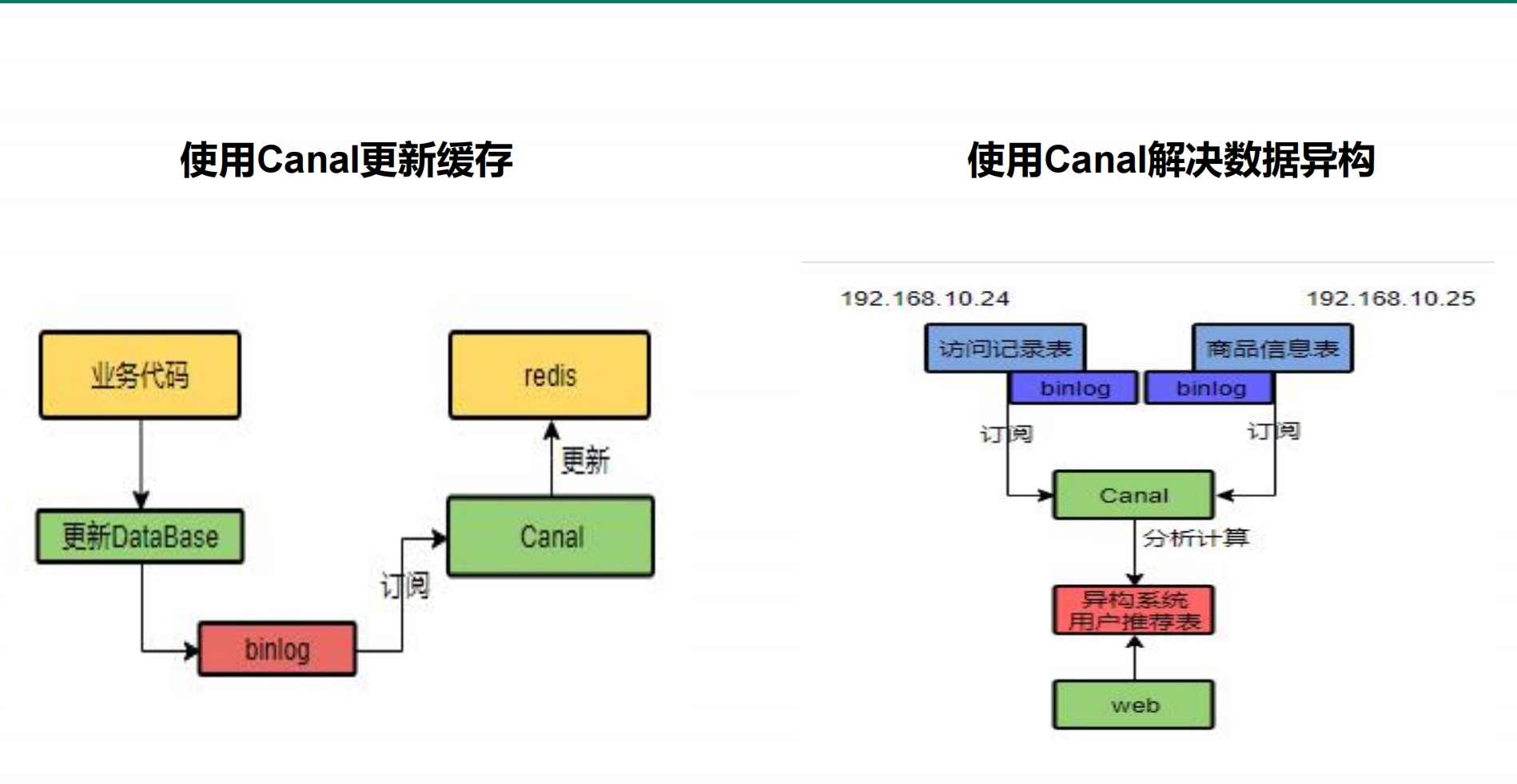
> canal可以作为MySQL的从库, 当MySQL中的数据更新时, canal从库中的数据同步更新, 可以通过redis来订阅canal, 当canal发生了更新, 可以将这些更新同步到Redis, 完美解决了缓存一致性问题
> 但是, 不建议使用canal, 因为会增加整体系统的复杂度, 中间将变多, 吞吐量和响应时间参数都变差
### 结论
1. 针对于用户数据(订单数据, 用户数据)不需要考虑缓存一致性问题
> **因为用户数据只有当前用户可以操作, 因此对于这个数据的并发量只可能为1, 发生大并发的概率极小, 因此, 缓存一致性问题几乎不存在**
> **因此, 针对于用户数据, 只需要考虑缓存的最终一致性即可**
2. 针对基础数据(分类, 商品介绍), 不需要考虑缓存一致性问题
> 因为基础数据不会影响任何实在有用的功能, 简单来说, 即使基础数据发生了缓存一致性问题, 和数据库数据不一致, 也不妨碍功能的使用, 也不会打扰你的荷包不被打劫
- 如果对缓存一致性要求不高, 即不要求实时一致性, 可以只过期时间保证最终一致性
- 如果对缓存一致性要求很高, 需要实时一致性, 可以基于上述的操作, 加上读写锁(相较于重量级锁好很多), 或者使用canal
- **我们不应该过度设计, 避免增加系统复杂性, 可以不加读写锁就别加**
- **遇到写多都少的情况, 可以避免使用缓存, 这样可以提高吞吐量, 避免读写锁**