缓存相关理论
# 缓存相关理论
## 什么数据是适合放入缓存?
1. <font color="purple">**时效性差的数据**</font>
> _时效性差: 一般表示数据改动的频率很低, 不会频繁更新的数据, 都会被称为时效性差_
> 示例: 比如商城业务中的分类, 几乎不可能改变, 其时效性很差, 因此查询分类可以使用缓存
2. <font color="purple">**数据一致性比较差的数据**</font>
> _数据一致性差: 一般表示查询出来的数据和数据库的数据可以不一样, 拥有很强大的包容性, 这种被称为数据一致性差
> 示例: 比如商品的热度, 假设到达了10w+, 多1还是少1没多大关系, 数据一致性差, 可以使用缓存
<font color="red">**总结: 读多写少的数据适合放入缓存**</font>
## 缓存的架构
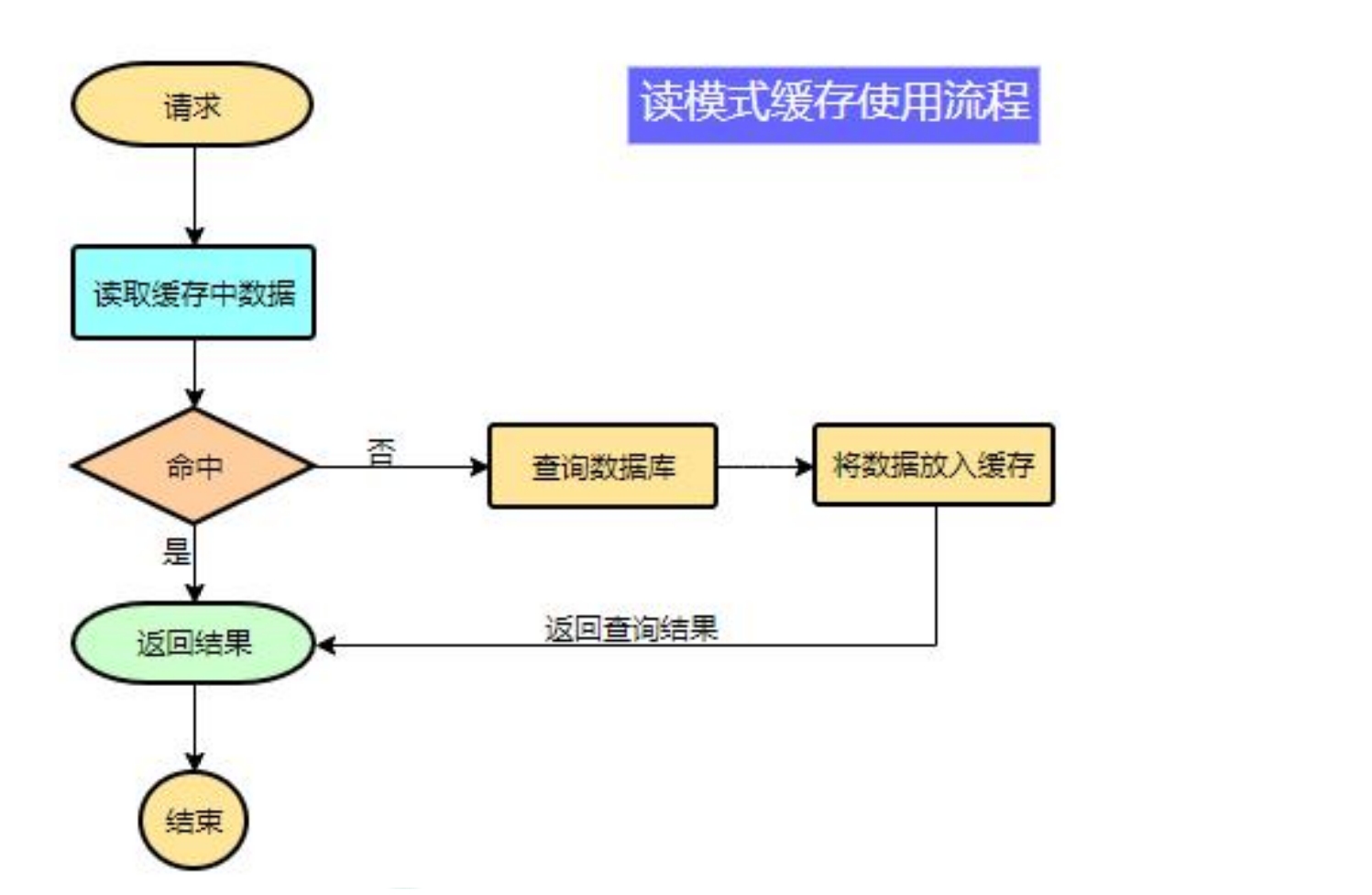
**伪码**
```java
var res = search_in_cache
if res exists then return res
else {
res = search_in_db
put_dada_in_cache
return cache
}
```
### 缓存需要设置过期时间!
1. 缓存一般存储在内存中, 如Redis, 如果缓存没有过期时间, 一直存储在内存中, 很可能会把内存消耗完, 导致内存紧张
2. 如果不设置过期时间, 如果某一次数据更新发生了错误, 没有更新缓存, 会导致缓存和数据库数据永久的数据不一致问题, 因此需要过期时间, 定期从缓存读取更新数据
## 缓存的类型
### 本地缓存
#### 本地缓存的实现
> **本地缓存一般用`HashMap`实现**, 因为`HashMap`采取的是哈希结构, 即数组+单向链表|红黑树, 在大量数据的情况下, 查询效率依然很高, 而且结构简单, KV键值对非常适合做缓存
#### 本地缓存存在的问题
1. <font color="red">**Heap Out Of Memory Error 堆内存溢出异常**</font>, 因为Java的对象存储在堆内存中, 而堆内存在运行时数据区中, 运行时数据区的大小是有限的, 一般比物理内存小很多, 如果不及时清除缓存, 缓存就会和其他业务数据抢堆内存, 进而导致**OOM**
2. <font color="red">**数据冗余问题**</font>, 在分布式场景下, 每一个微服务都有自己的缓存, 且缓存的数据是一模一样的, 会导致内存的浪费
3. <font color="red">**数据不一致问题**</font>, 在分布式的场景下, 如果一个微服务更新数据, 仅仅会把当前微服务的缓存更新了, 并没有同步更新其他微服务的缓存, 下次负载均衡到其他缓存的时候就会发生数据不一致问题
### 分布式缓存
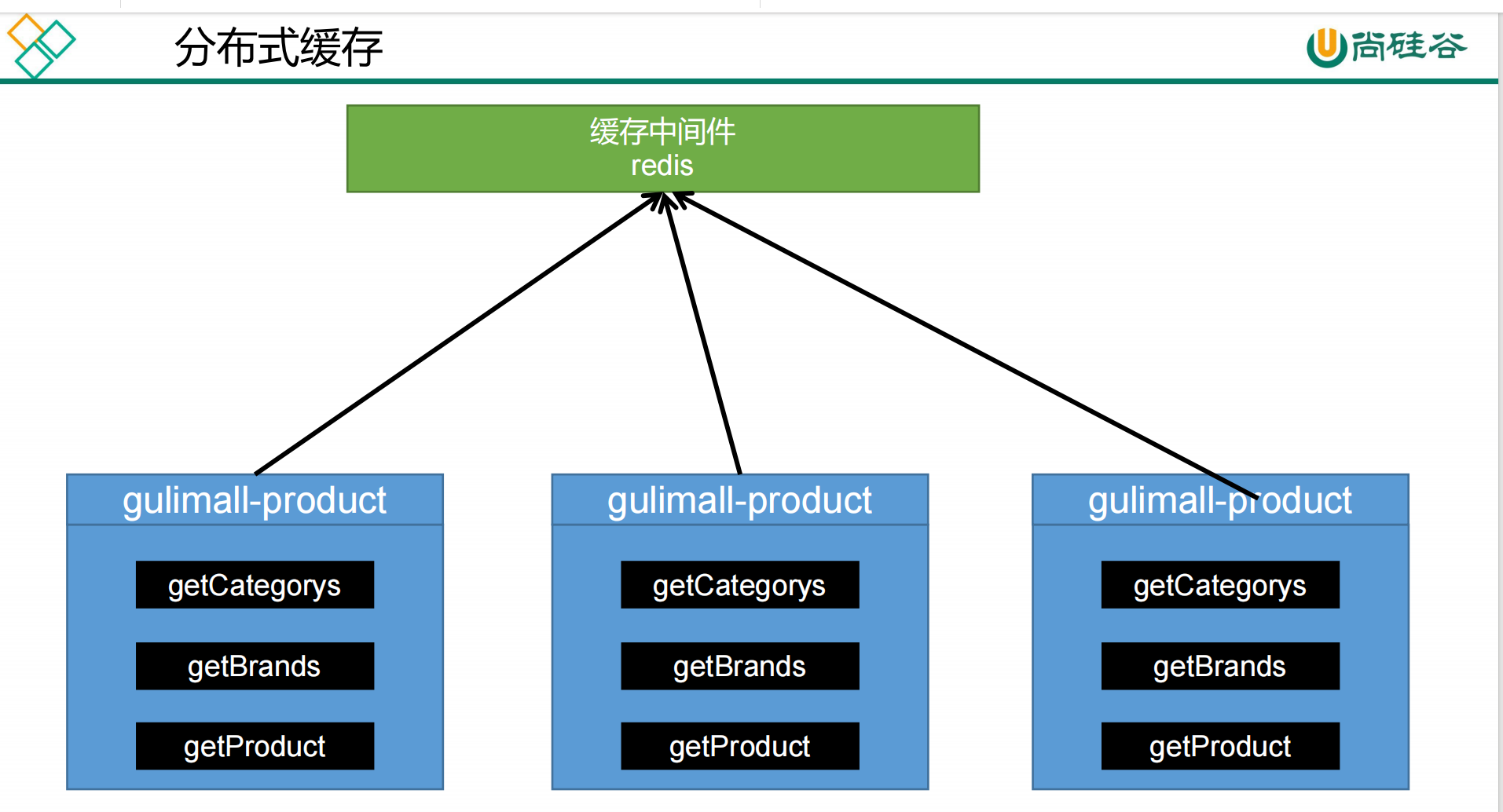
> 微服务首先会查询分布式缓存(该分布式缓存时唯一的), 判断是否存在, 若存在缓存直接返回, 不存在则查询数据库, 将结果保存缓存中并返回
> 由于多个微服务查询的是同一个分布式缓存, 解决了数据一致性和冗余的问题, 而且分布式缓存不占用运行时数据区, 不会造成**OOM**
#### 分布式缓存的实现
> **Redis**
#### Redis如何解决内存紧张问题?
> Redis可以采取分片存储, 即构造一个Redis集群, 集群中的每一个节点仅存储一部分数据, 从而缓解内存紧张问题
## Redis的整合
```xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
<version>5.2.1.RELEASE</version>
</dependency>
```
```yml
redis:
host: 192.168.10.131
port: 6379
password: root
```
> **`lettuce-core`5.2.1版本成功解决了直接内存溢出的问题**
### 为什么会直接内存溢出
直接内存并不在运行时数据区中, 没有GC机制, 需要开发者手动回收内存, 因此, 内存回收的难度很大, 回收的不好极易出现内存溢出, 因此, 当发现内存溢出的时候可以选择一个更高的版本或者切换框架
### 解决方案的查找
[作者回答](https://github.com/lettuce-io/lettuce-core/issues/721)
> 查找思路很简单, 在官方issue查找对应的关键词, 然后再查找作者的口述, 直到找到解决方案的版本即可
## 缓存方案
### 缓存的值以JSON的形式存储
> 以三级分类而言, 我想把整个三级分类的数据缓存起来, 一种缓存方案是把这个对象的序列化结果缓存起来, 读取缓存的时候反序列化即可
> 但是有一个严重的问题, 即无法跨平台, 因为该序列化的结果仅仅在JVM的环境下才可以被解析
> ***而JSON不同, 任何语言都可以解析JSON, 使用JSON作为值, 跨平台性很好, 无论是`C++`还是`python`都可以读取, 因此用JSON存储***
## 缓存带来的问题
### 缓存穿透
#### 什么是缓存穿透
> 前提: 当我们查询一个数据库不存在的记录时, 我们会自作聪明返回一个空值, 并不缓存这个空值, 这会有很严重的后果, 缓存穿透
> 在百万并发的条件下, 如果都查询一个不存在的记录, 缓存不可能有该条记录, 因此, 所有的请求都需要查询数据库, 这样绕过缓存而直接查询数据库的结果, 被称为缓存穿透
#### 缓存穿透会造成什么后果
> 缓存穿透会造成所有的请求绕过缓存直接查询数据库, 一方面, 吞吐量和响应时间的指标大大降低, 另一方面, 很可能是DB的压力过大, 从而导致宕机, 从而引发整个后端集群的崩溃
#### 如何解决缓存穿透
> 即使记录不存在, 也需要缓存起来, 避免缓存穿透, 并加入短暂的过期时间
### 缓存雪崩
#### 什么是缓存雪崩
> 前提: 同一时间, 创建了大量缓存, 且缓存的过期时间是一样的
> 在百万并发的条件下, 如果查询这些数据, 有可能某一个时间内这些数据同时过期, 导致百万请求无法查询缓存, 需要查询数据库, 这就是缓存雪崩
#### 缓存雪崩造成什么后果
> 缓存雪崩会造成所有的请求绕过缓存直接查询数据库, 一方面, 吞吐量和响应时间的指标大大降低, 另一方面, 很可能是DB的压力过大, 从而导致宕机, 从而引发整个后端集群的崩溃
#### 如何解决缓存雪崩
> 在缓存数据的时候, 缓存的时间需要在一个共同的技术上加上一个随机值, 从而实现每一个缓存的过期时间都不同, 避免缓存雪崩
### 缓存击穿
#### 什么是缓存击穿
> 前提: 有一个热点KEY, 该热点KEY会被百万并发访问
> 在百万兵发的条件下, 如果这百万请求同时访问该热点KEY, 若热点KEY恰好此刻过期, 会导致百万请求无法查询缓存, 需要查询数据库, 这就是缓存击穿
#### 缓存击穿造成什么后果
> 缓存击穿会造成所有的请求绕过缓存直接查询数据库, 一方面, 吞吐量和响应时间的指标大大降低, 另一方面, 很可能是DB的压力过大, 从而导致宕机, 从而引发整个后端集群的崩溃
#### 如何解决缓存击穿
> 缓存击穿的解决需要依靠**双端检锁机制**
### 缓存穿透-本地锁解决方案
#### 为什么使用双端检锁
> 首先判断了缓存是否存在, 若存在直接返回, 为了避免百万并发同时读取数据库, 因此, 这里可以加上一个重量级锁`synchronized`, 让多个请求线程争抢锁资源, 最终仅有一个线程能成功查询数据库, <font color="red">**重量级锁的目的就是为了不让百万兵发同时读数据库**</font>
> 获取重量级锁后仍需要判断缓存是否存在, 或返回缓存, 因为即使第一个争抢到了锁资源, 最终也会放弃锁资源, 其他拿到锁资源也会去查询数据库, 为了杜绝其他人查询数据库, 可以再判断一次缓存, 因为第一个人查出来了, 因此缓存有了, 不需要走数据库了, 这样就解决了缓存击穿难题
#### 获取谁的锁资源对象
> 获取当前对象的锁资源, 因为当前对象有注解`@Service`, 即当前对象作为组件注册到IOC容器中, IOC
容器中的组件都是单例的, 因此, 在单体应用的前提下, 很适合
#### 锁-时序问题
> 经历压测可知, 在高并发的场景下, 查询了两次数据库, 这是因为保存缓存的操作在重量级锁范围之外, 这可能会导致, 当我们查询完数据后, 释放重量级锁, 但是此刻并没有将数据缓存起来, 其他线程请求成功获取锁资源, 发现此刻缓存没有该数据, 又查询了一次数据库, 这就是为什么数据库被多次查询的原因
> 为了避免该情况, 我们可以将数据的缓存放入锁的范围内, 确保数据被缓存起来, 其他线程再去查
#### 本地锁在分布式下的问题
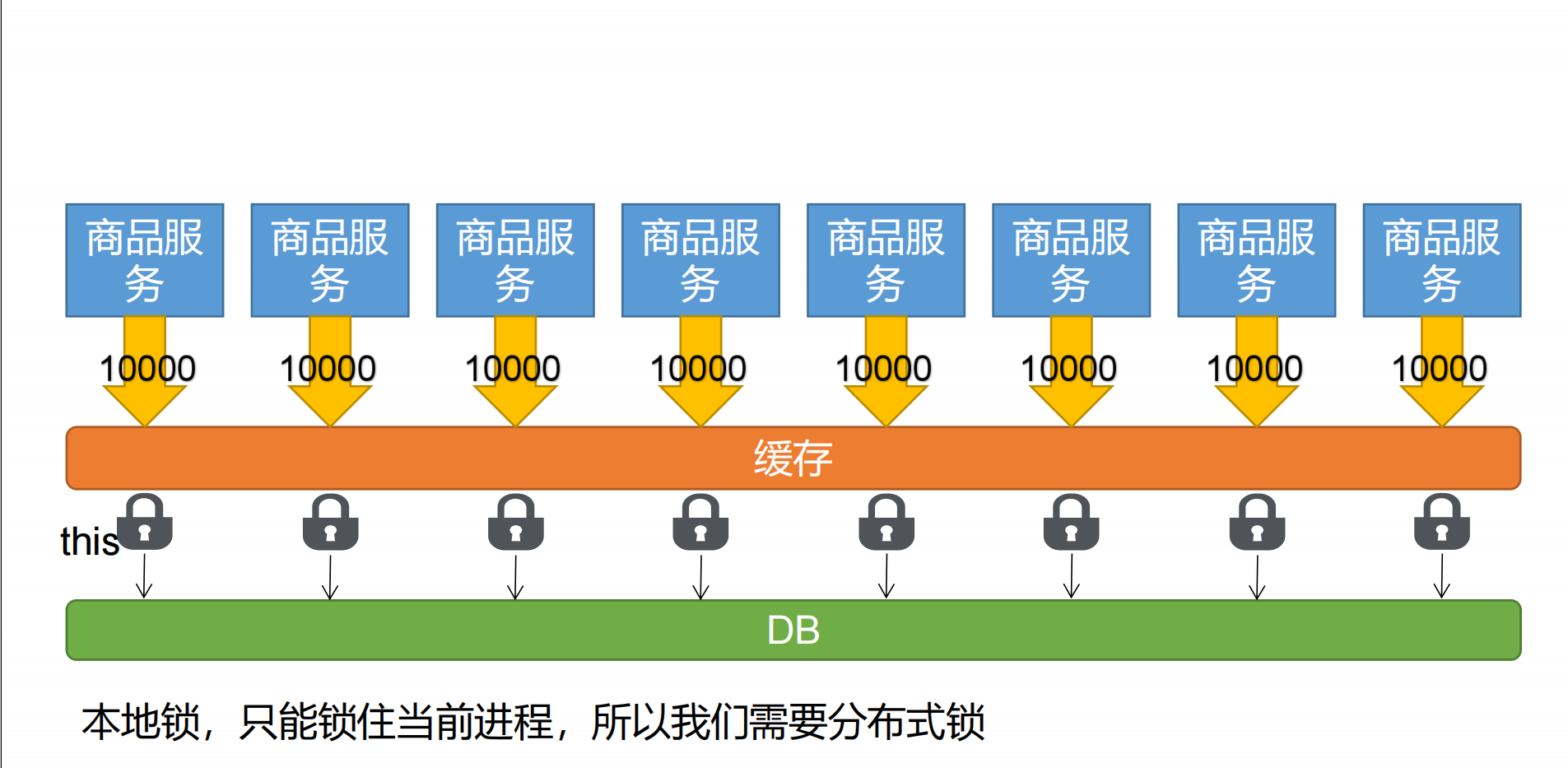
> 本地锁在一个IOC容器中确实只有一个, 本地锁可以把整个进程锁起来, 但是,在分布式场景下, 每一个微服务都拥有一个IOC容器, 这代表了有多少个微服务, 就有多少个锁资源, 这会导致并发的状况, 即每一个微服务允许一个查询, N个微服务有N个查询
## 分布式锁
### 本地锁和分布式锁的区别
> 本地锁和分布式锁本质上是一样的, 它们都是只有一个锁资源, 这个锁资源只能被一个线程所获取, 但是, 它们最大的不同是, 本地锁只能当前进程获取该锁资源, 而分布式锁, 跨进程的线程, 即多个进程的线程都可以参与争抢分布式锁资源
### 分布式锁的原理
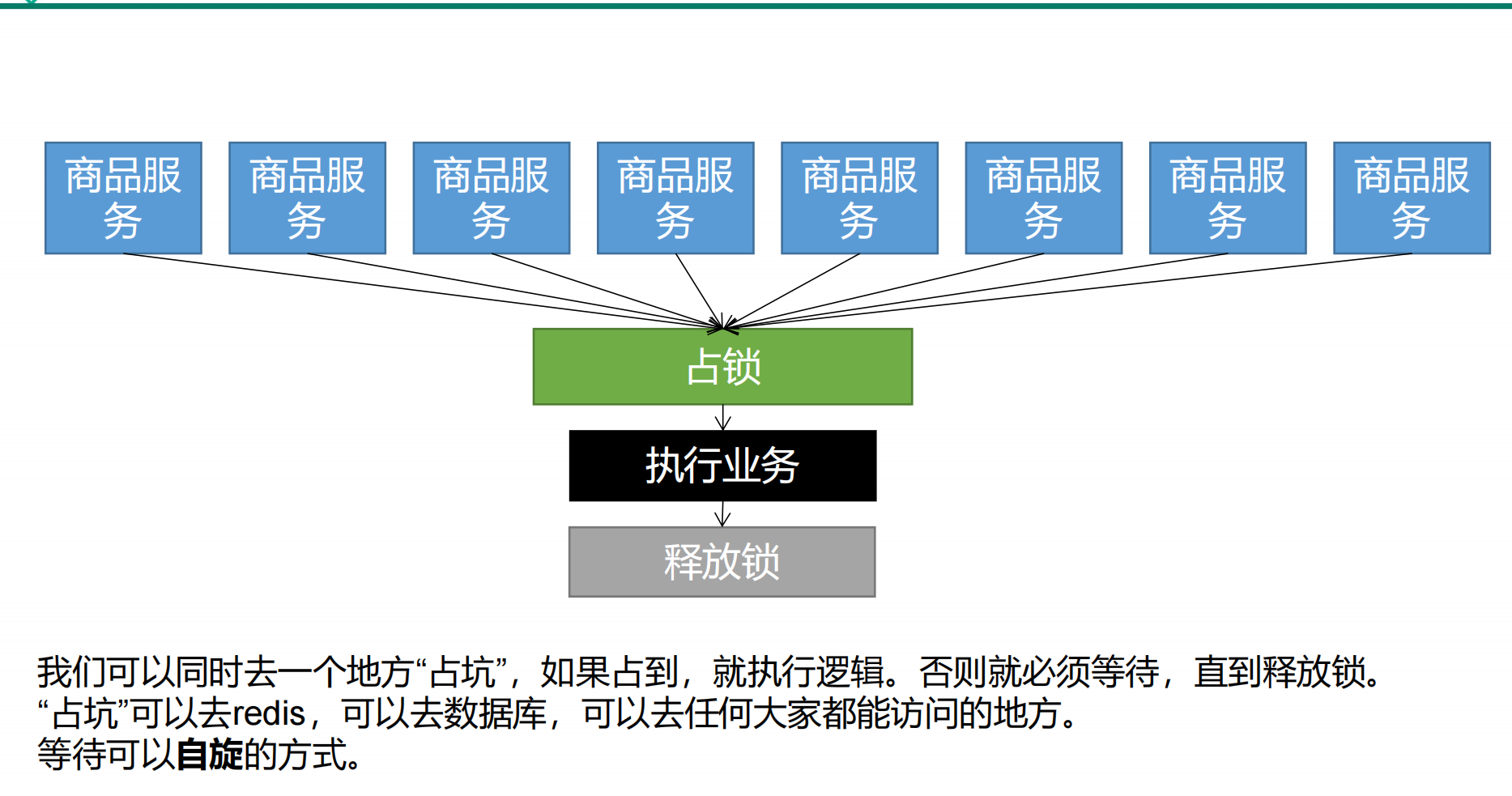
### 分布式锁为什么用Redis实现?
> 因为分布式锁的本质是占坑, 而实现该的方式有很多种, 例如: 数据库, 因为数据库表中记录的主键是无序不可重复的, 因此, 一个id只能有一条记录, 因此, 分布式场景下, 可以通过多线程争抢创建记录, 若能创建成功, 则说明获取锁资源, 从而达到了占坑的目的
> 但是, 数据库有一个致命的缺陷, 即记录是存储在磁盘的, 需要磁盘IO, 效率低, 为了解决磁盘IO的情况, 可以采取更为高效便捷的Redis, 通过Redis的`SETNX`命令, 该命令仅有当`key`不存在的时候才能返回`true`, 否则返回`false`, 可以实现占坑的目的
> 并且该命令具有原子性, 换而言之, 加锁具有原子性, 非常好
> 通过点击`Xshell`, 右键 -> 发送键输入到(K) -> 所有会话(A) 模拟线程争抢锁资源
### 分布式锁如何实现?
#### 版本1
```java
private Map<String, List<Catalog2VO>> getDataAndCacheItWithHadoopSyncSource() {
while (true) {
//1. 尝试获取获取锁资源
if (!redisTemplate.opsForValue().setIfAbsent("lock", "1")) { // 获取锁资源失败
continue; // 这里的CAS自旋采取了循环的方式, 自选不可以采取递归的方式, 否则很容易出现StackOverFlow
}
try {
// 2. 业务逻辑代码
Map<String, List<Catalog2VO>> map = getCategoryLevel2Or3FromDBLocalSync();
String map2Json = ""; // 记录不存在, 把空串缓存起来
if (map != null && !map.isEmpty()) { // 查询出来的记录有可能为空, 因此需要解决缓存穿透问题
// 数据库成功查询出对应的记录, 需要转换JSON, 然后存储
map2Json = JSON.toJSONString(map);
}
// 缓存需要设置过期时间, 避免因宕机造成永久数据不一致问题
// 创建随机值, 避免缓存雪崩, 随即量 1min ~ 1day
long randomTime = RandomUtils.nextLong(1, 1440);
redisTemplate.opsForValue().set(ProductConstant.Cache.CACHE_CATEGORY_2_OR_3, map2Json,
(ProductConstant.Cache.CACHE_DEPRECATED_MINUTES + randomTime), TimeUnit.MINUTES);
return map;
}finally {
redisTemplate.delete("lock"); // 避免出现异常导致分布式锁释放失败
}
}
}
```
##### 问题
> 虽然上面解决了<font color="blue">**因为异常而无法释放锁资源**</font>,的问题, 但是, 系统在执行过程中可能会发生宕机, <font color="red">**突然宕机可能会导致删除记录的代码没有被执行**</font>, 这也会导致锁资源释放失败, 进而导致<font color="purple">**死锁**</font>
> <font color="balck">**死锁发生的条件: 异常, 宕机**</font>
##### 解决
> ***可以给kv对加上过期时间, 即使遇到宕机或异常或者其他不可抗力因素导致的记录删除失败, 锁资源释放失败, 最终都可以通过过期时间自动销毁, 解决了死锁问题***
#### 版本2(根据上述指导意见升级)
```java
private Map<String, List<Catalog2VO>> getDataAndCacheItWithHadoopSyncSource() {
while (true) {
//1. 尝试获取获取锁资源
if (!redisTemplate.opsForValue().setIfAbsent("lock", "1")) { // 获取锁资源失败
continue; // 这里的CAS自旋采取了循环的方式, 自选不可以采取递归的方式, 否则很容易出现StackOverFlow
}
// 加上过期时间
redisTemplate.expire("lock", 100, TimeUnit.SECONDS); // 过期时间为100s
try {
// 2. 业务逻辑代码
Map<String, List<Catalog2VO>> map = getCategoryLevel2Or3FromDBLocalSync();
String map2Json = ""; // 记录不存在, 把空串缓存起来
if (map != null && !map.isEmpty()) { // 查询出来的记录有可能为空, 因此需要解决缓存穿透问题
// 数据库成功查询出对应的记录, 需要转换JSON, 然后存储
map2Json = JSON.toJSONString(map);
}
// 缓存需要设置过期时间, 避免因宕机造成永久数据不一致问题
// 创建随机值, 避免缓存雪崩, 随即量 1min ~ 1day
long randomTime = RandomUtils.nextLong(1, 1440);
redisTemplate.opsForValue().set(ProductConstant.Cache.CACHE_CATEGORY_2_OR_3, map2Json,
(ProductConstant.Cache.CACHE_DEPRECATED_MINUTES + randomTime), TimeUnit.MINUTES);
return map;
}finally {
redisTemplate.delete("lock"); // 避免出现异常导致分布式锁释放失败
}
}
}
```
##### 问题
> 即使优化过后, 仍会导致死锁问题, <font color="red">**因为创建记录即获取所资源和设置过期时间并非原子性的**</font>, 这会导致在创建完所资源后到设置过期时间间形成一段空档期, 如果个在这段空档期宕机, 过期时间无法成功设置, 锁资源也无法成功释放, 仍然会导致死锁问题
##### 解决
> ***必须要保证获取所资源和设置过期时间的原子性***
#### 版本3(根据上述指导意见升级)
```java
private Map<String, List<Catalog2VO>> getDataAndCacheItWithHadoopSyncSource() {
while (true) {
//1. 尝试获取获取锁资源
if (!redisTemplate.opsForValue().setIfAbsent("lock", "1", 100, TimeUnit.SECONDS)) { // 获取锁资源失败 // 加上过期时间
continue; // 这里的CAS自旋采取了循环的方式, 自选不可以采取递归的方式, 否则很容易出现StackOverFlow
}
try {
// 2. 业务逻辑代码
Map<String, List<Catalog2VO>> map = getCategoryLevel2Or3FromDBLocalSync();
String map2Json = ""; // 记录不存在, 把空串缓存起来
if (map != null && !map.isEmpty()) { // 查询出来的记录有可能为空, 因此需要解决缓存穿透问题
// 数据库成功查询出对应的记录, 需要转换JSON, 然后存储
map2Json = JSON.toJSONString(map);
}
// 缓存需要设置过期时间, 避免因宕机造成永久数据不一致问题
// 创建随机值, 避免缓存雪崩, 随即量 1min ~ 1day
long randomTime = RandomUtils.nextLong(1, 1440);
redisTemplate.opsForValue().set(ProductConstant.Cache.CACHE_CATEGORY_2_OR_3, map2Json,
(ProductConstant.Cache.CACHE_DEPRECATED_MINUTES + randomTime), TimeUnit.MINUTES);
return map;
}finally {
redisTemplate.delete("lock"); // 避免出现异常导致分布式锁释放失败
}
}
}
```
##### 问题
这里记录的过期时间即锁资源的施放时间是一个定值, 执行时间很可能大于该过期时间, 一旦执行时间比过期时间长, 在执行过程中锁资源自动释放, 其他线程争抢执行权并执行, <font color="red">**会出现并发的情况**</font>, 而且当该线程执行结束后, <font color="red">**会把其他线程的锁资源给释放了, 即释放了其他线程的锁资源**</font>, 这是**非常严重的问题**
##### 解决
***为了解决释放其他线程锁资源的问题, 可以给记录的值加上一个唯一标识, 属于自己的唯一标识才释放, 否则不释放***
#### 版本4
```java
private Map<String, List<Catalog2VO>> getDataAndCacheItWithHadoopSyncSource() {
String uuid = UUID.randomUUID().toString();
while (true) {
//1. 尝试获取获取锁资源
if (!redisTemplate.opsForValue().setIfAbsent("lock", uuid, 100, TimeUnit.SECONDS)) { // 获取锁资源失败 // 加上过期时间
continue; // 这里的CAS自旋采取了循环的方式, 自选不可以采取递归的方式, 否则很容易出现StackOverFlow
}
try {
// 2. 业务逻辑代码
Map<String, List<Catalog2VO>> map = getCategoryLevel2Or3FromDBLocalSync();
String map2Json = ""; // 记录不存在, 把空串缓存起来
if (map != null && !map.isEmpty()) { // 查询出来的记录有可能为空, 因此需要解决缓存穿透问题
// 数据库成功查询出对应的记录, 需要转换JSON, 然后存储
map2Json = JSON.toJSONString(map);
}
// 缓存需要设置过期时间, 避免因宕机造成永久数据不一致问题
// 创建随机值, 避免缓存雪崩, 随即量 1min ~ 1day
long randomTime = RandomUtils.nextLong(1, 1440);
redisTemplate.opsForValue().set(ProductConstant.Cache.CACHE_CATEGORY_2_OR_3, map2Json,
(ProductConstant.Cache.CACHE_DEPRECATED_MINUTES + randomTime), TimeUnit.MINUTES);
return map;
}finally {
if (redisTemplate.opsForValue().get("lock").equals(uuid)) { // 一样说明是自己的, 可以释放
redisTemplate.delete("lock"); // 避免出现异常导致分布式锁释放失败
}
}
}
}
```
##### 问题
> 在发送请求获取值和本地UUID相比较的时候, 该操作和删除锁资源并不是一个原子性操作, 因此, 在返回来的结果和UUID比较成功到释放锁资源存在一段间隔, 这个间隔有可能锁资源已经被自动释放了, 且其他线程获取了该所资源, 这又会导致当前线程错误的释放其他线程的锁资源
##### 解决
> ***采用`LUA`脚本解决释放的原子性问题***
#### 版本5
```java
private Map<String, List<Catalog2VO>> getDataAndCacheItWithHadoopSyncSource() {
String uuid = UUID.randomUUID().toString();
while (true) {
//1. 尝试获取获取锁资源
if (!redisTemplate.opsForValue().setIfAbsent("lock", uuid, 100, TimeUnit.SECONDS)) { // 获取锁资源失败 // 加上过期时间
continue; // 这里的CAS自旋采取了循环的方式, 自选不可以采取递归的方式, 否则很容易出现StackOverFlow
}
try {
// 2. 业务逻辑代码
Map<String, List<Catalog2VO>> map = getCategoryLevel2Or3FromDBLocalSync();
String map2Json = ""; // 记录不存在, 把空串缓存起来
if (map != null && !map.isEmpty()) { // 查询出来的记录有可能为空, 因此需要解决缓存穿透问题
// 数据库成功查询出对应的记录, 需要转换JSON, 然后存储
map2Json = JSON.toJSONString(map);
}
// 缓存需要设置过期时间, 避免因宕机造成永久数据不一致问题
// 创建随机值, 避免缓存雪崩, 随即量 1min ~ 1day
long randomTime = RandomUtils.nextLong(1, 1440);
redisTemplate.opsForValue().set(ProductConstant.Cache.CACHE_CATEGORY_2_OR_3, map2Json,
(ProductConstant.Cache.CACHE_DEPRECATED_MINUTES + randomTime), TimeUnit.MINUTES);
return map;
}finally {
String luaScript = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
redisTemplate.execute(new DefaultRedisScript<>(luaScript), Arrays.asList("lock"), uuid);
// 第一个参数是一个脚本对象, 直接创建即可, 第二个是key数组, 对应着LUA脚本中的KEY[1], 第三个是ARGV数组, 对应着脚本中的ARGV[1]
}
}
}
```
## BUG修复
### 测试的时候, 组件无法注入的问题
> 首先排查的是自动配置类`RedisAutoConfigure`, 发现没有任何的爆红, 自动配置类没有问题
> 其次看报错信息` Unable to find a @SpringBootConfiguration, you need to use @ContextConfiguration or @SpringBootTest(classes=...) with your test`, 这个说明了测试类的包路径必须和原类的包路径一致, 否则无法注入