集群的知识架构
# 集群的知识架构
## 为什么需要集群?或者说集群的目的是什么?
- **高可用**: 通俗点来说, 如果目标应用需要访问MySQL获取数据, 当这个MySQL因故宕机之后, 对这个应用毫无影响, 这被称为高可用
- 要想实现高可用, 必须通过集群, 否则, 若只有一台MySQL, 当他宕机的时候, 整个功能都不可用, 造成单点故障
- **突破数据量限制**: 通俗点来说, 本来整个服务最多能存储100w条数据, 现在能存储1kw条数据, 即突破数量限制
- 如果要实现突破数量限制, 依旧离不开集群, 在集群情况下, 可以做分片存储, 即每一个节点都存储一点, 如果在单机模式下, 存储容量有限, 不可能比分片存储的存储能力强
- **数据备份容灾**: 最简单的场景下, 如果一个MySQL的数据被误删了, 在集群模式下可以通过其他节点的数据备份来恢复数据, 在单机模式下, 数据丢失, 还有更多数据丢失的场景...
- **压力分担**: 通俗点来说, 一共有100w的请求, 在集群模式下每一个节点共同分担这100w, 相较于单机模式的独立承担, 压力更小, 容错更强, 不易宕机
## 集群的存储形式
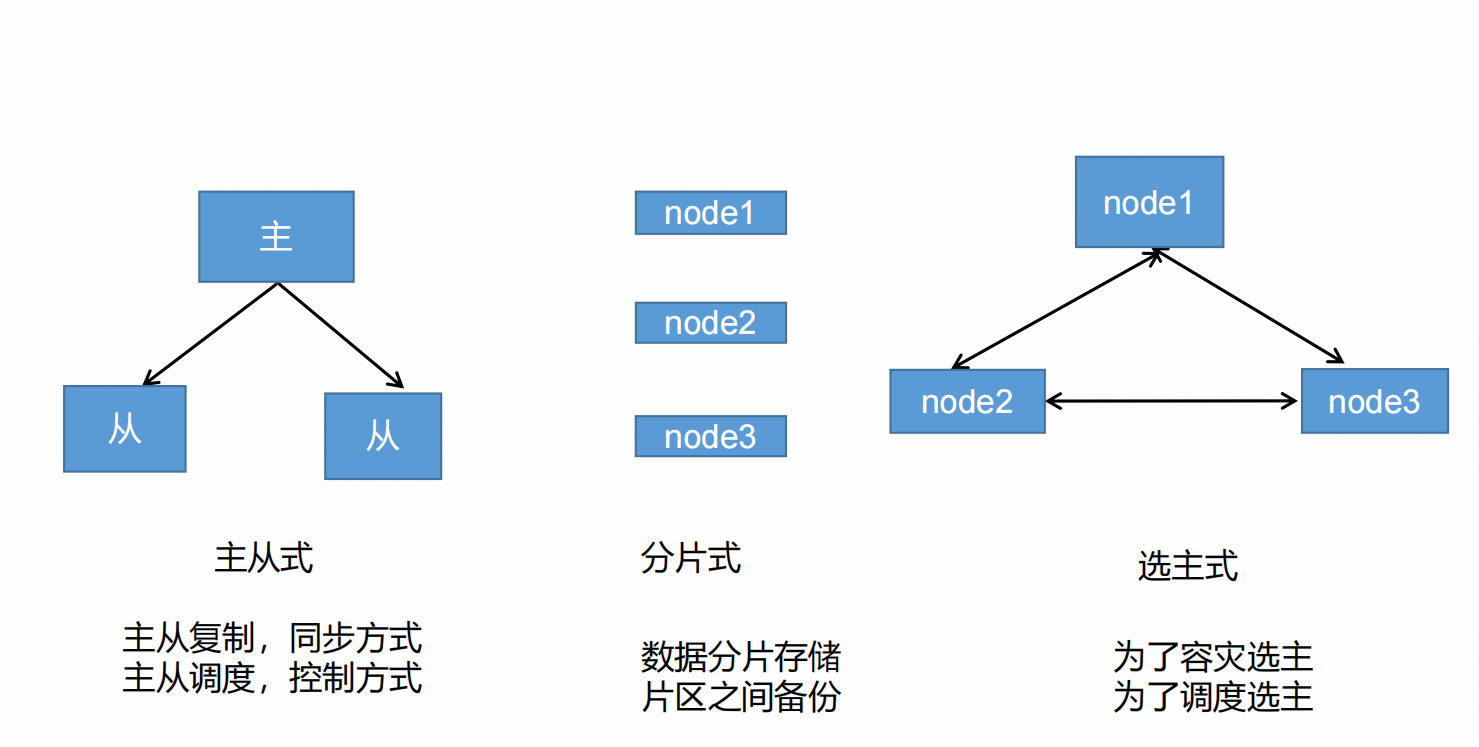
> 特别说明: K8S是基于主从式的, 采用主从调度, 它不具有选主的能力, 因此, K8S的主节点需要构造一个集群
## 构建MySQL集群
### MMM模式
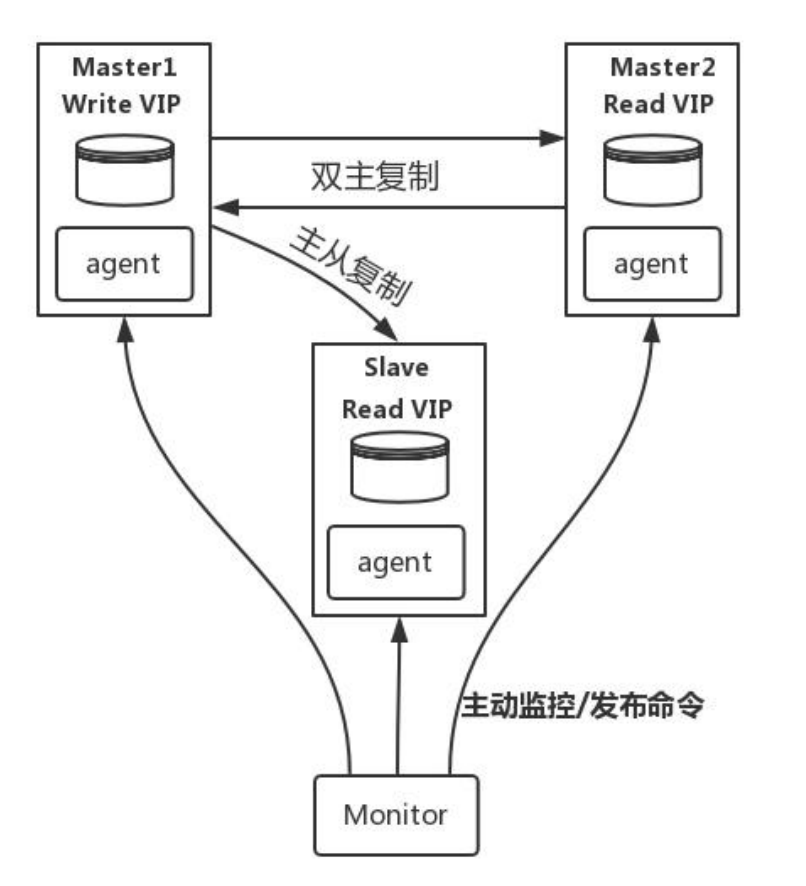
*MySQL-MMM 是 Master-Master Replication Manager for MySQL(mysql 主主复制管理器)的简称,是 Google 的开源项目(Perl 脚本)。MMM 基于 MySQL Replication 做的扩展架构,主要用来监控 mysql 主主复制并做失败转
移。其原理是将真实数据库节点的IP(RIP)映射为虚拟 IP(VIP)集。mysql-mmm 的监管端会提供多个虚拟 IP(VIP),包括一个可写 VIP,多个可读 VIP,通过监管的管理,这些 IP 会绑定在可用 mysql 之上,当某一台 mysql 宕机时,监管会将 VIP迁移至其他 mysql。在整个监管过程中,需要在 mysql 中添加相关授权用户,以便让 mysql 可以支持监理机的维护。授权的用户包括一个mmm_monitor 用户和一个 mmm_agent 用户,如果想使用 mmm 的备份工具则还要添加一个 mmm_tools 用户。*
#### MMM模式的原理
> **MMM模式主要是靠虚拟IP集来实现服务的高可用的, 类似于NGINX的高可用**
> 虚拟IP集一共有两大类, 一个是可读虚拟IP, 一个可写虚拟IP, 由上面的图可知, 这里有两个主节点, 实际上, **整个集群只能有一个主节点, 那么另外一个主节点自动降为从节点, 主节点和从节点进行主从复制**
> 虚拟IP会自动将读写分离, 读操作通过可读的虚拟IP访问从节点, 写操作通过可写虚拟IP访问主节点
> **当一个主节点宕机的时候, 另一个主节点(当前为从节点)自动晋升为主节点, 写操作的虚拟IP自动漂移到新的主节点中, 以前的主节点容灾恢复后, 自动降为从节点**
### <font color="red">InnoDBCluster模式</font>
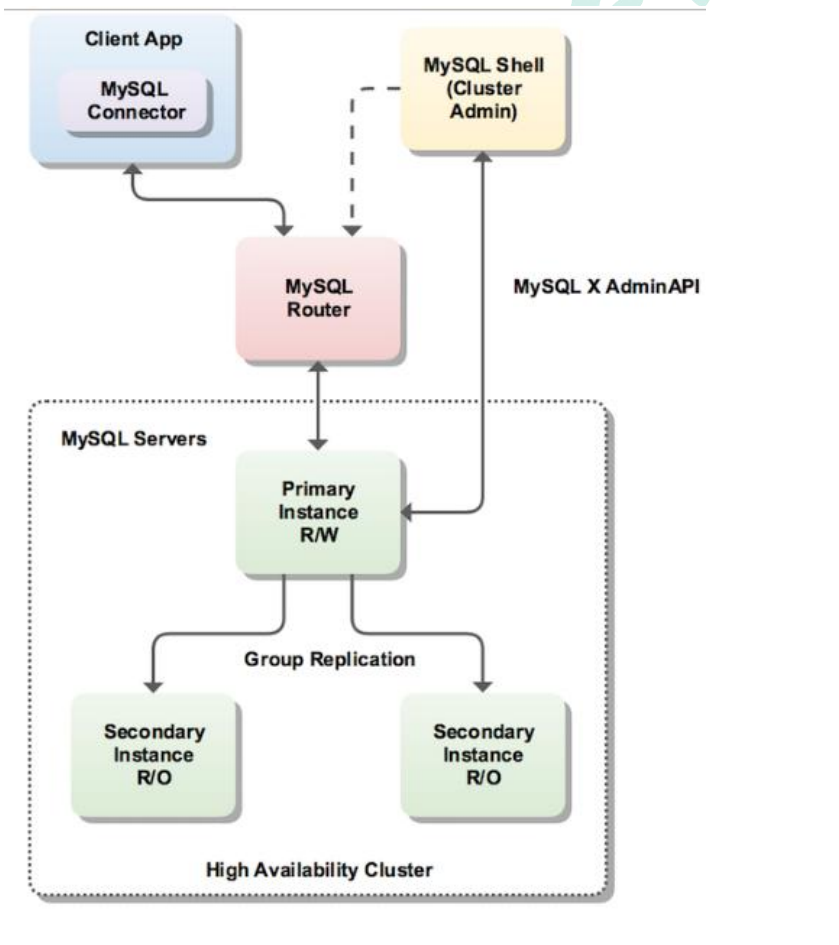
*InnoDB Cluster 支持自动 Failover、强一致性、读写分离、读库高可用、读请求负载均衡,横向扩展的特性,是比较完备的一套方案。但是部署起来复杂,想要解决 router单点问题好需要新增组件,如没有其他更好的方案可考虑该方案。 InnoDB Cluster 主要由 MySQL Shell、MySQL Router 和 MySQL 服务器集群组成,三者协同工作,共同为MySQL 提供完整的高可用性解决方案。MySQL Shell 对管理人员提供管理接口,可以很方便的对集群进行配置和管理,MySQL Router 可以根据部署的集群状况自动的初始化,是客户端连接实例。如果有节点 down 机,集群会自动更新配置。集群包含单点写入和多点写入两种模式。在单主模式下,如果主节点 down 掉,从节点自动替换上来,MySQL Router 会自动探测,并将客户端连接到新节点*
#### InnoDBCluster模式的原理
> **首先, 明确的是, 主节点和从节点之间是遵顼主从复制的, 除了遵循主从复制, 主节点可以进行读写操作, 而从节点是制度操作**
> 整体的工作流程是, 客户端发送请求的时候, 无论是什么请求, 都不直接访问节点(无论是主节点还是从节点), 而是访问代理服务器, 通过代理服务器将请求分发, 不同的请求分发到不同的节点
> **如果从节点down掉了, 路由会重新分配主从, 将从节点晋升为主节点**
### 总结
#### 共同点
1. **它们都是主从复制的**
2. **读写分离**
### 企业实战的原理
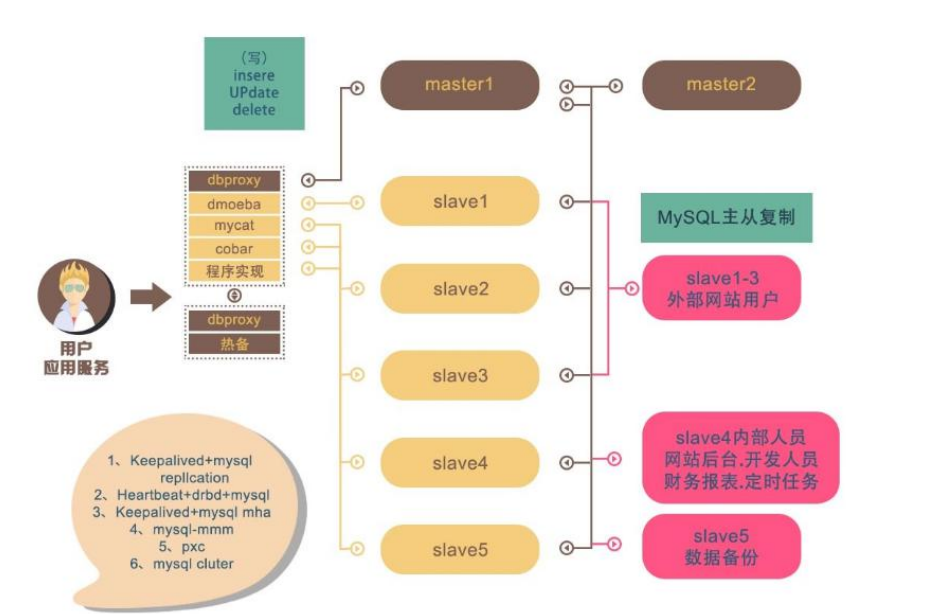
1. 所有的数据库请求都不访问任何一个节点, 只访问代理服务器, 由代理服务器分发请求, 实现读写分离
2. 这里有两个主节点, 主要是为了防止主节点崩溃, 这样的好处是, 如果主节点没问题, 备份主节点主要和主节点做主从同步, 如果主节点宕机了, 备份主节点立刻补位, 实现了高可用
3. 这里有很多从节点, 从节点实现了场景划分, 即从库服务的对象实现了划分, 有些是专门做备份的, 有些给后端管理系统的, 有些给用户服务的, 这样最大力度减小了数据库服务压力
### 为什么要分库分表
[MySQL数据量与CURD效率的关系图](https://www.processon.com/embed/651576b4ee3af44dd46b0efa)
> 我们从这个图可知, 当数据量越大, 他的各项性能都下降的非常厉害, 所以, 我们不能让一个数据库的表承担过大的数据量, 所以, 我们不得不分库分表, 从而提高效率
> 如果进行了分库分表, 从这个关系图可以看出, 效率会高很多
### 主从复制的原理
> 主节点的任何写操作都会被记录到一个binlong日志里面, 从节点通过读取binlong日志, 从而一比一还原主节点的操作, 从而在从节点上操作, 获取和主节点一样的数据, 从而实现主从同步
## 构建MySQL集群
```
[client]
default-character-set=utf8mb4
[mysql]
default-character-set=utf8mb4
[mysqld]
init_connect='SET collation_connection = utf8mb4_unicode_ci'
init_connect='SET NAMES utf8mb4'
character-set-server=utf8mb4
collation-server=utf8mb4_unicode_ci
skip-character-set-client-handshake
skip-name-resolve
server_id=1 #[每一个都不一样]
log-bin=mysql-bin
read-only=0 #[从节点是1]
binlog-do-db=btimall_ums
binlog-do-db=bitmall_pms
binlog-do-db=bitmall_oms
binlog-do-db=bitmall_sms
binlog-do-db=bitmall_wms
binlog-do-db=bitmall_admin
replicate-ignore-db=mysql
replicate-ignore-db=sys
replicate-ignore-db=information_schema
replicate-ignore-db=performance_schema
```
### 主节点配置
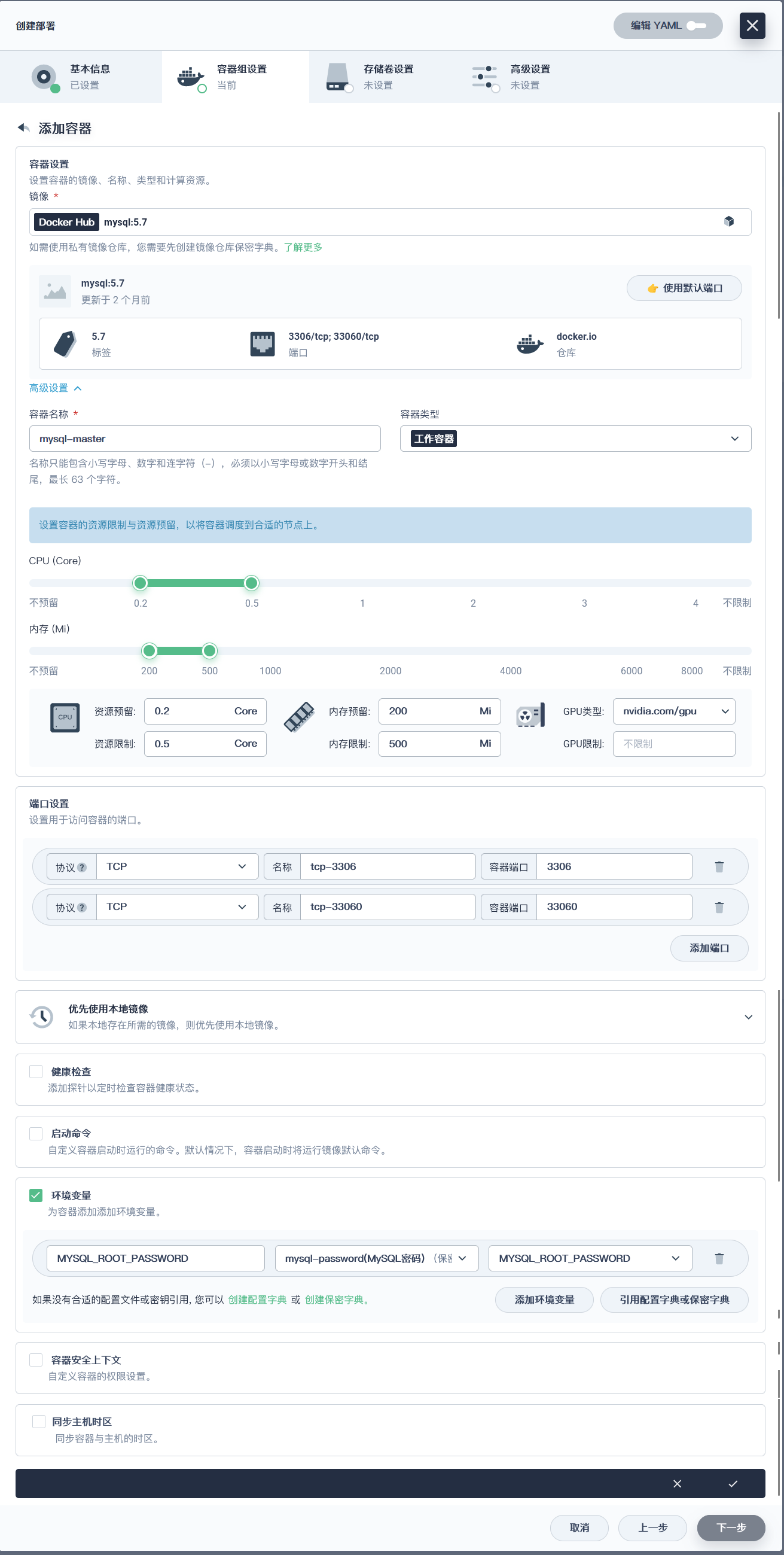
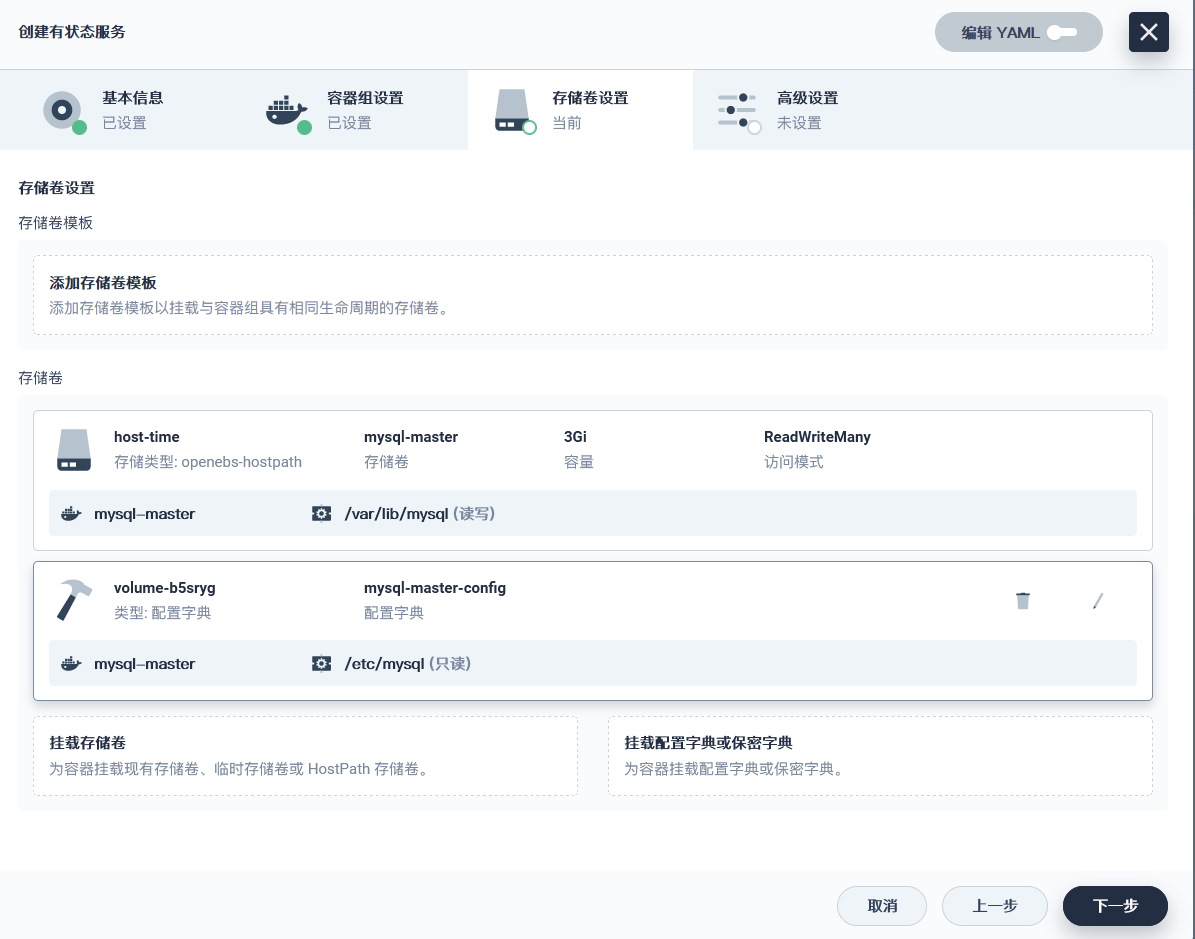
---
#### 坑
##### 关于创建PVC的坑
> <font color="red">**访问模式必须是ReadWriteOnce**</font>, 如果是**ReadWriteMany**, 就会发生无法调度容器的错误
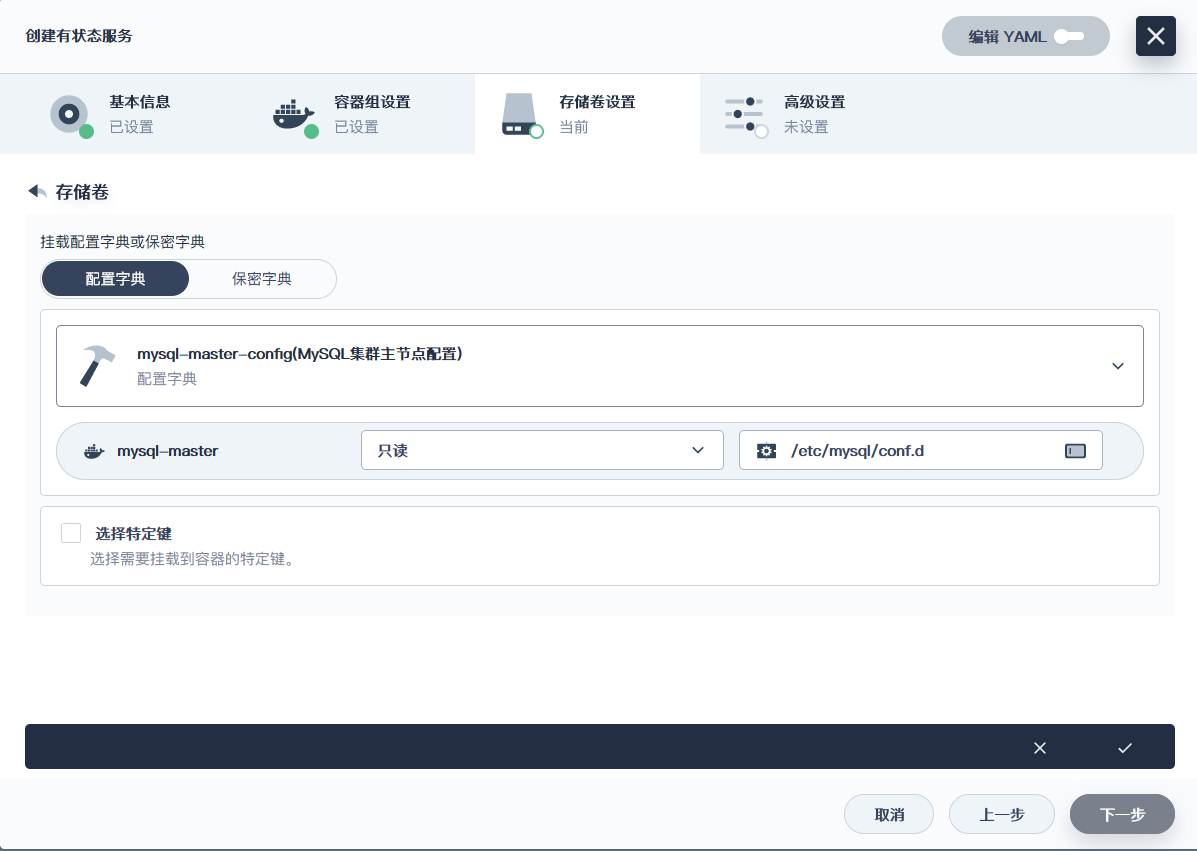
##### 挂载配置文件的坑
> 理论上来说, 我们挂载的目录是`/etc/mysql`, 然后对`my.cnf`这个配置继续挂载到`my.cnf`, 但是, 这样MySQL启动会报错, 说找不到`conf.d`目录, 因此, 我们挂载的目录改成图片所示的`/etc/mysql/conf.d`
##### 关于配置文件的坑
```cnf
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
init_connect='SET collation_connection = utf8_unicode_ci' init_connect='SET NAMES utf8' character-set-server=utf8
collation-server=utf8_unicode_ci
skip-character-set-client-handshake
skip-name-resolve
```
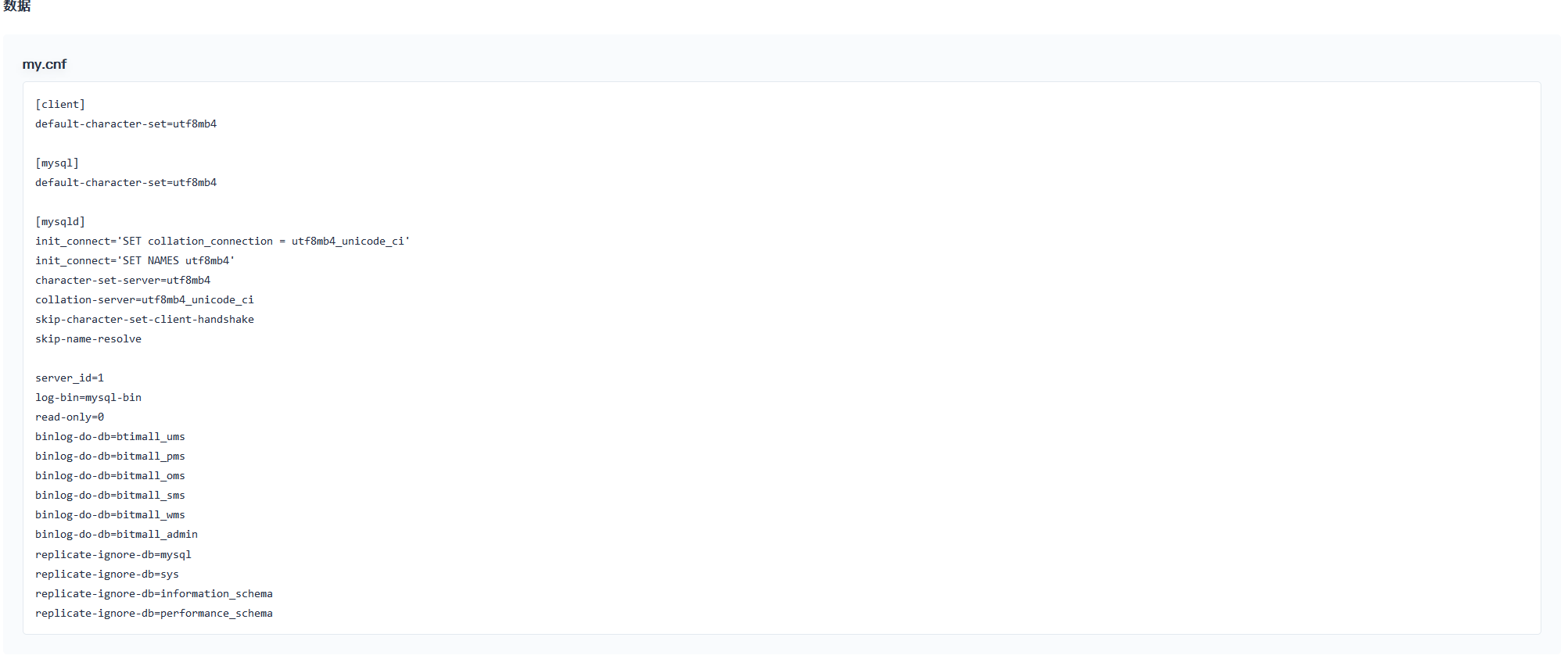
> 这是老师给的配置文件, 这个配置文件的字符编码设置有问题, 会导致容器重启, 需要改成下面的
```cnf
[client]
default-character-set=utf8mb4
[mysql]
default-character-set=utf8mb4
[mysqld]
init_connect='SET collation_connection = utf8mb4_unicode_ci'
init_connect='SET NAMES utf8mb4'
character-set-server=utf8mb4
collation-server=utf8mb4_unicode_ci
skip-character-set-client-handshake
skip-name-resolve
```
### 从节点配置
> **这里PVC的创建方式和主节点的一模一样, 配置文件也大致一样, 只有服务器id(递增)和 只读配置(1)需要改变**
> **其他配置和主节点一模一样**
### 授权用户
1. 通过kubeSphere进入MySQL容器, 先登录
2. 授权root用户
```sql
grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option;
flush privileges;
```
3. 添加同步用户
```sql
GRANT REPLICATION SLAVE ON *.* to 'backup'@'%' identified by '123456';
```
4. 查看主节点状态(记住File的值)
```sql
show master status\G;
```
### 配置从节点同步主节点
1. 授权root用户
```sql
grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option;
flush privileges;
```
2. 连接主节点
```sql
change master to master_host='mysql-master.bitmall',master_user='backup',master_password='123456',master_log_file='mysql-bin.000005',master_log_pos=0,master_port=3306;
```
> `master_host`是kubesphere提供给pod的域名, 在pod那里查找就行了
> `master-password`必须是backup的密码, 否则有一个状态会一直处于connecting状态
> `master_log_file`通过查看主节点状态得知
> 后面的是固定的
3. 启动从库同步
```sql
start slave;
```
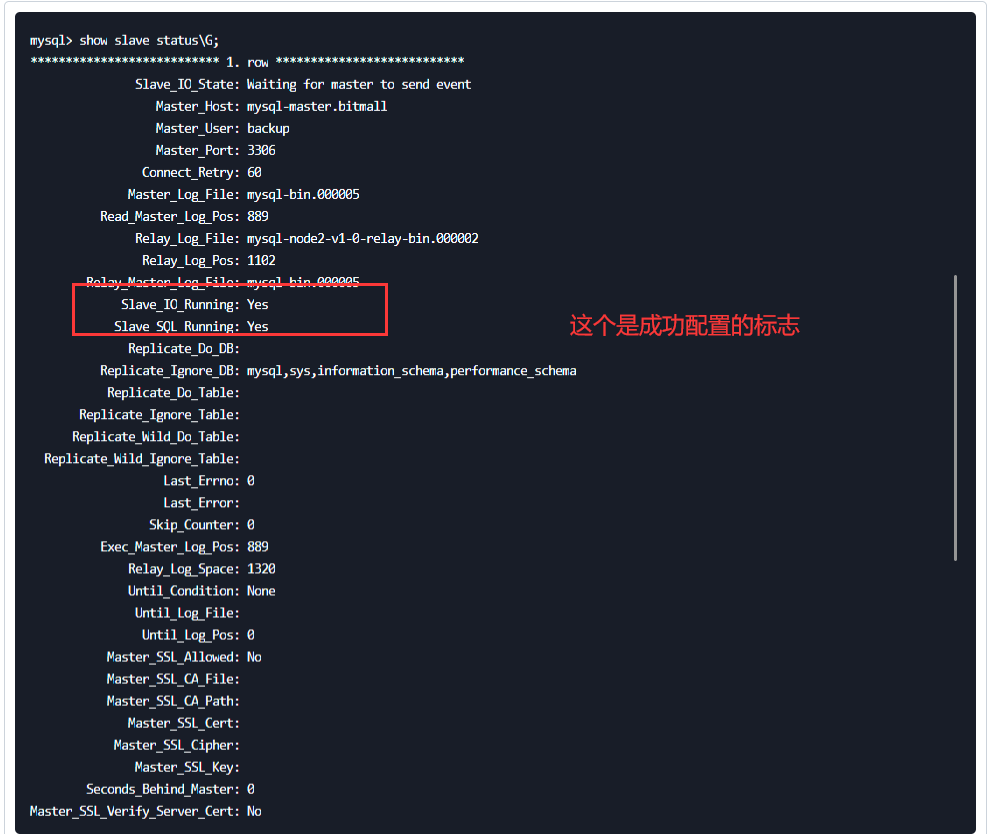
4. 查看状态
```sql
show slave status\G;
```
设置错了可以执行下面的指令重置从节点, 从节点的配置是一模一样的
```sql
stop slave;
reset slave all;
```
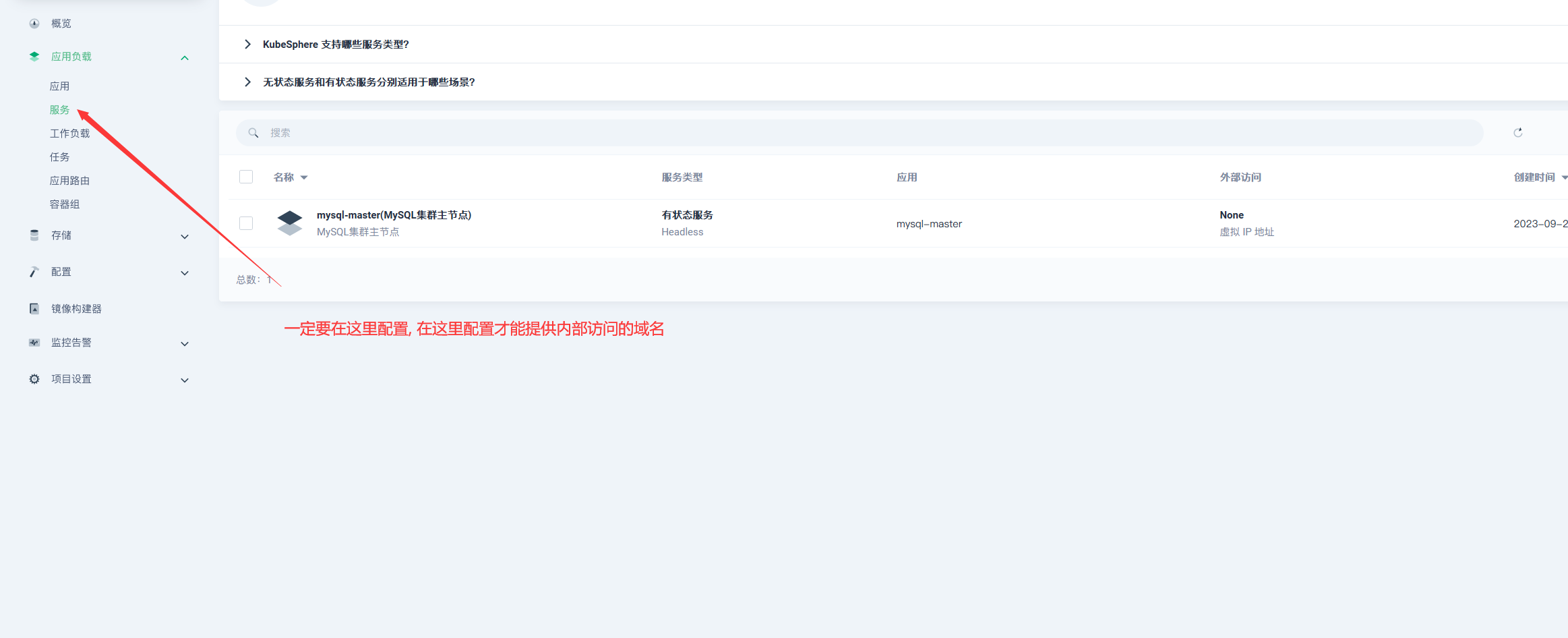
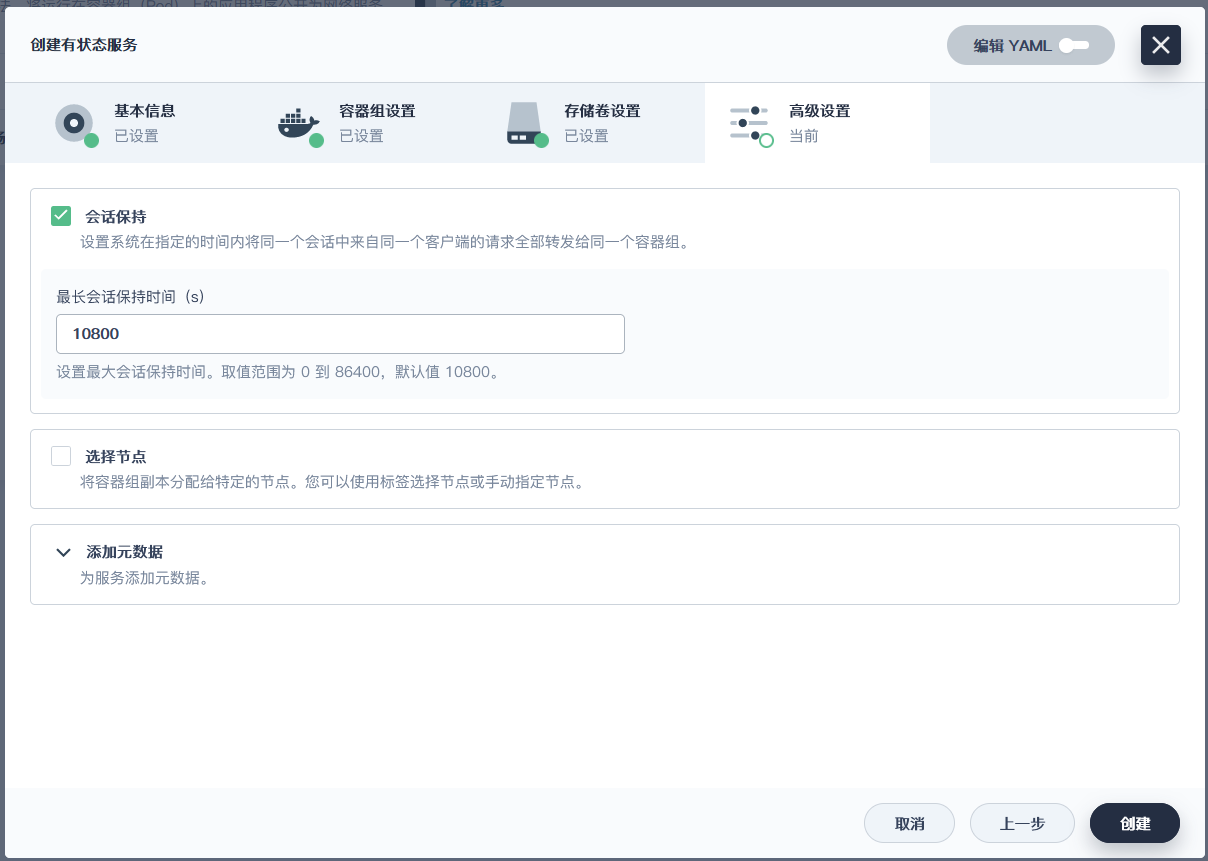
### 将MySQL的节点都以端口的形式暴露出现(全部操作都一样)
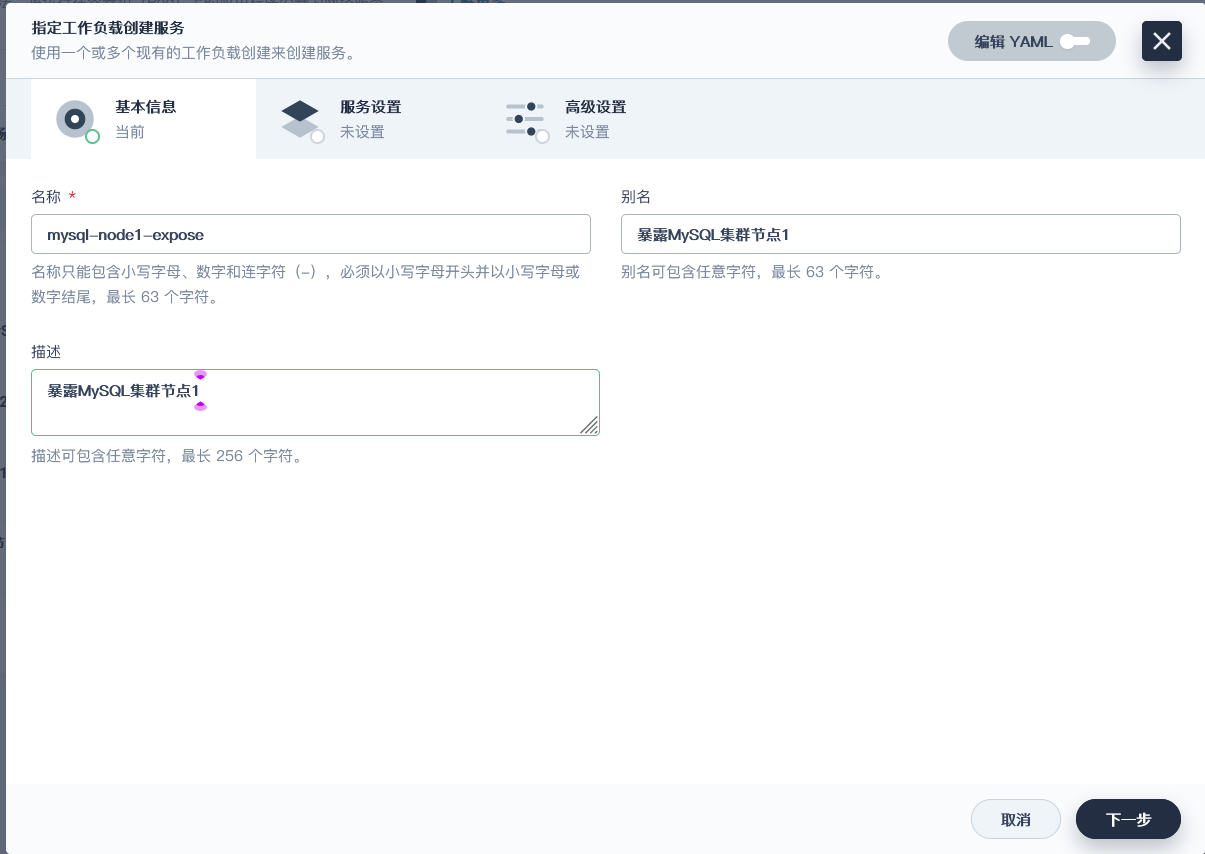
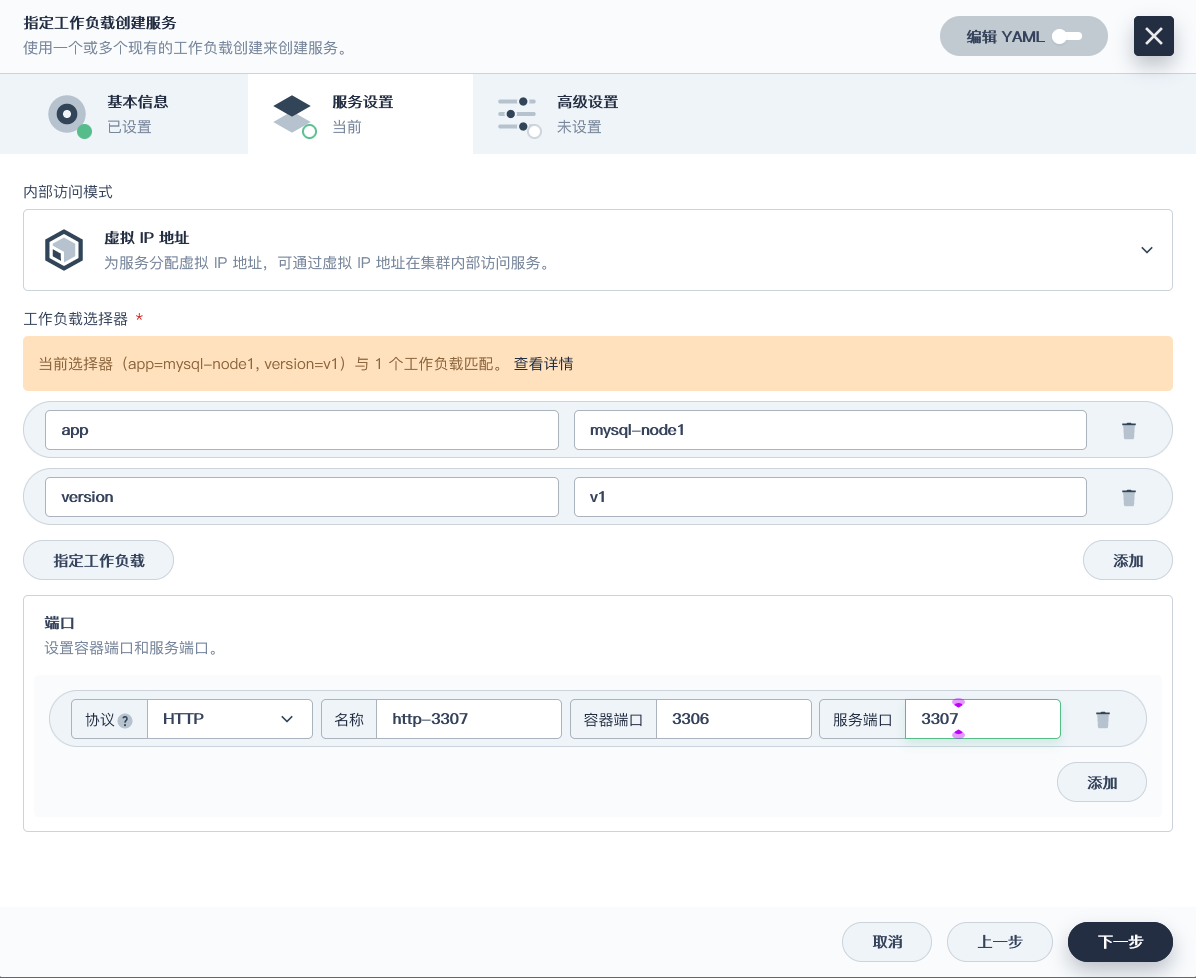
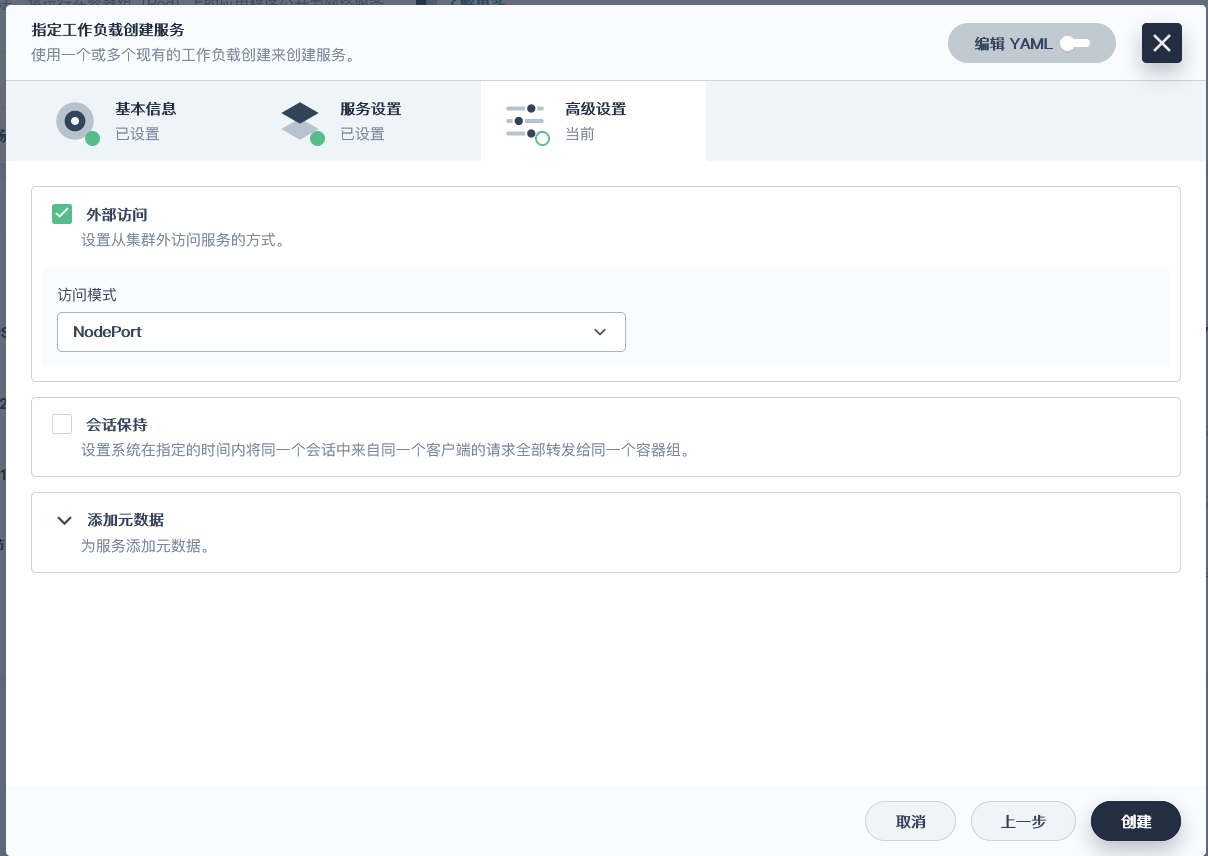
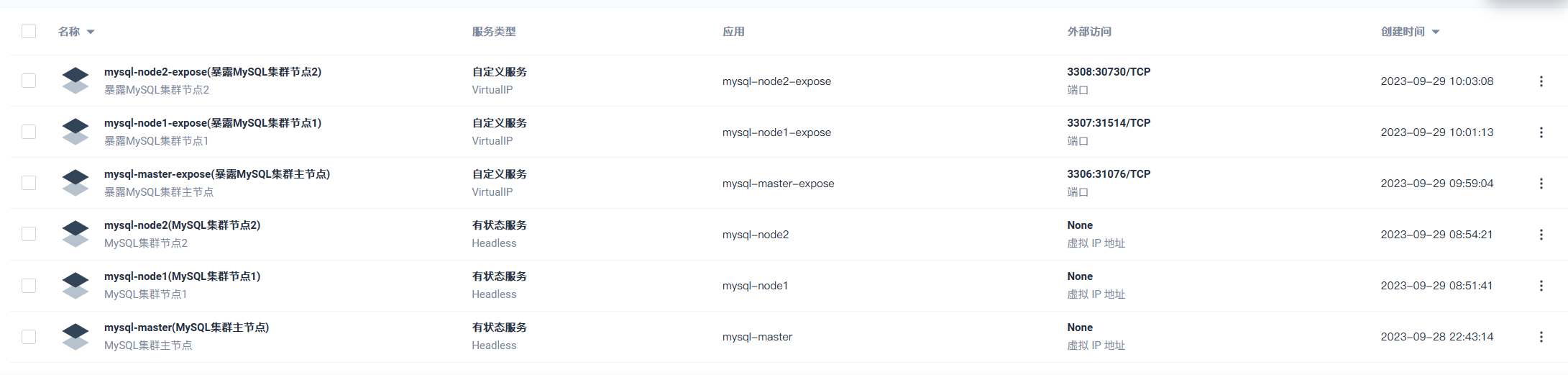
> 这里的服务端口号是pod暴露给service的, 集群pod很可能在同一个节点内, 为了避免端口冲突, 设置每一个端口都不同, 并不是外部访问的端口(NodePort)
### Navcicat连接并测试主从同步
#### 创建一个可供远程访问的超级管理员用户
```sql
GRANT ALL PRIVILEGES ON *.* TO 'remote'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION;
```
> **这里我不测试了, 我这里的主从复制没有任何的问题**
## ShardingShpere
### 为什么要用ShardingShpere?
> 如果我们想要分库分表, 传统来说, 我们可以根据id的奇偶性手动选择不同的数据库不同的表进行连接, 这种方案确实可行, 但是, 就现实意义来说, 太麻烦了, , 而且某个节点宕机了, 很可能导致某个数据丢失, 所以, 不用这种
> 为了解决分库分表的痛点, ShardingShpere能提供一系列的解决方案, 因此, ShardingShpere用于分库分表, 读写分离非常的方便
### 介绍
[**官方概览**](https://shardingsphere.apache.org/document/current/cn/overview/)
> 总结: ShardingProxy和ShardingJDBC最大的区别是, 一个需要访问代理对象, 由代理对象通过分库分表, 读写分离, 一个直接访问数据库, 不需要经过代理对象
> **最终我们采用ShardingProxy, 有中心更加契合我们的代码**
### 架构(如果不想像我一样配置, 可以直接下载我的镜像)
#### 下载ShardingSphere-Proxy
[下载4.1.0版本](https://archive.apache.org/dist/shardingsphere/)
#### 配置文件
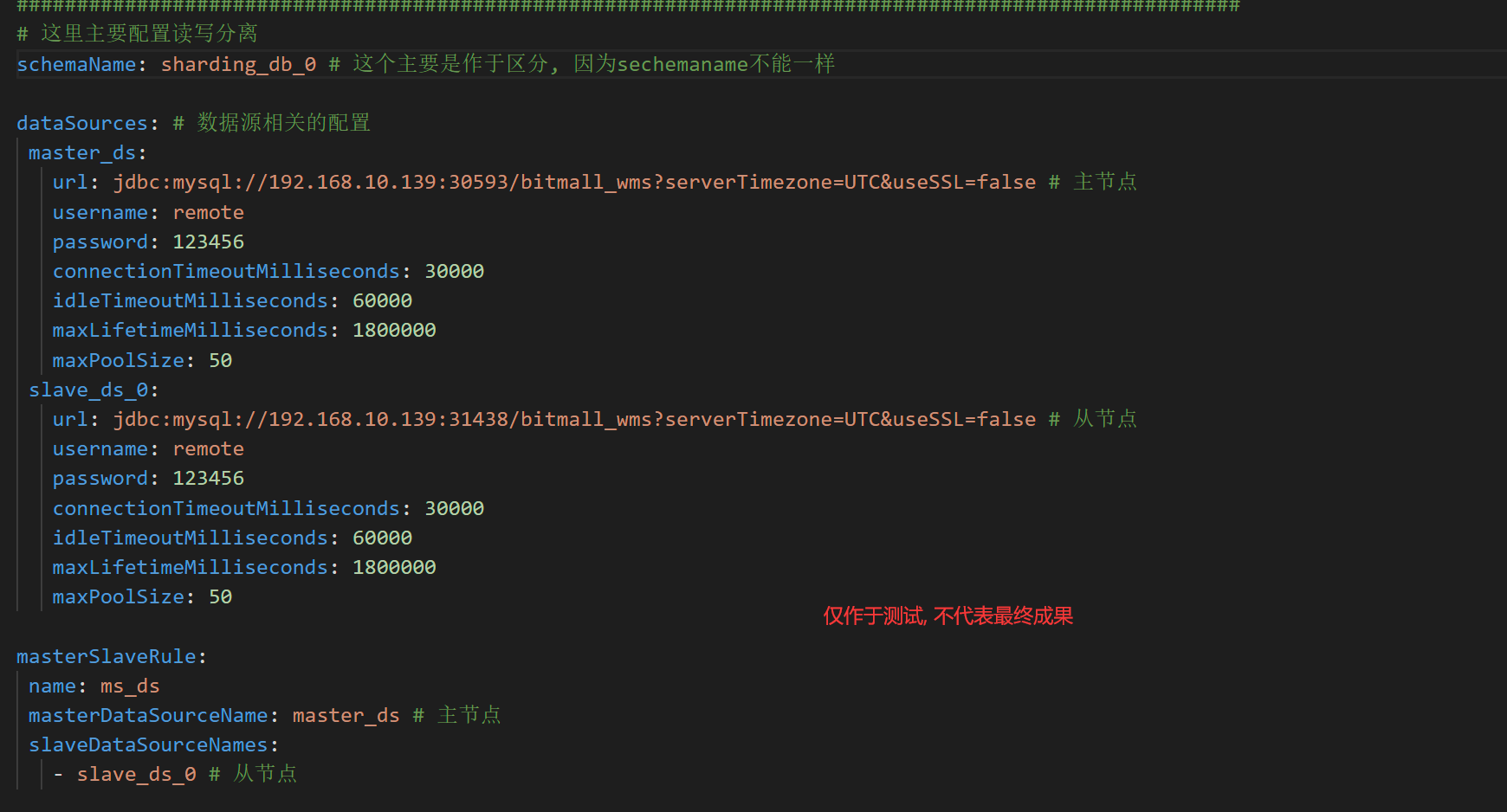
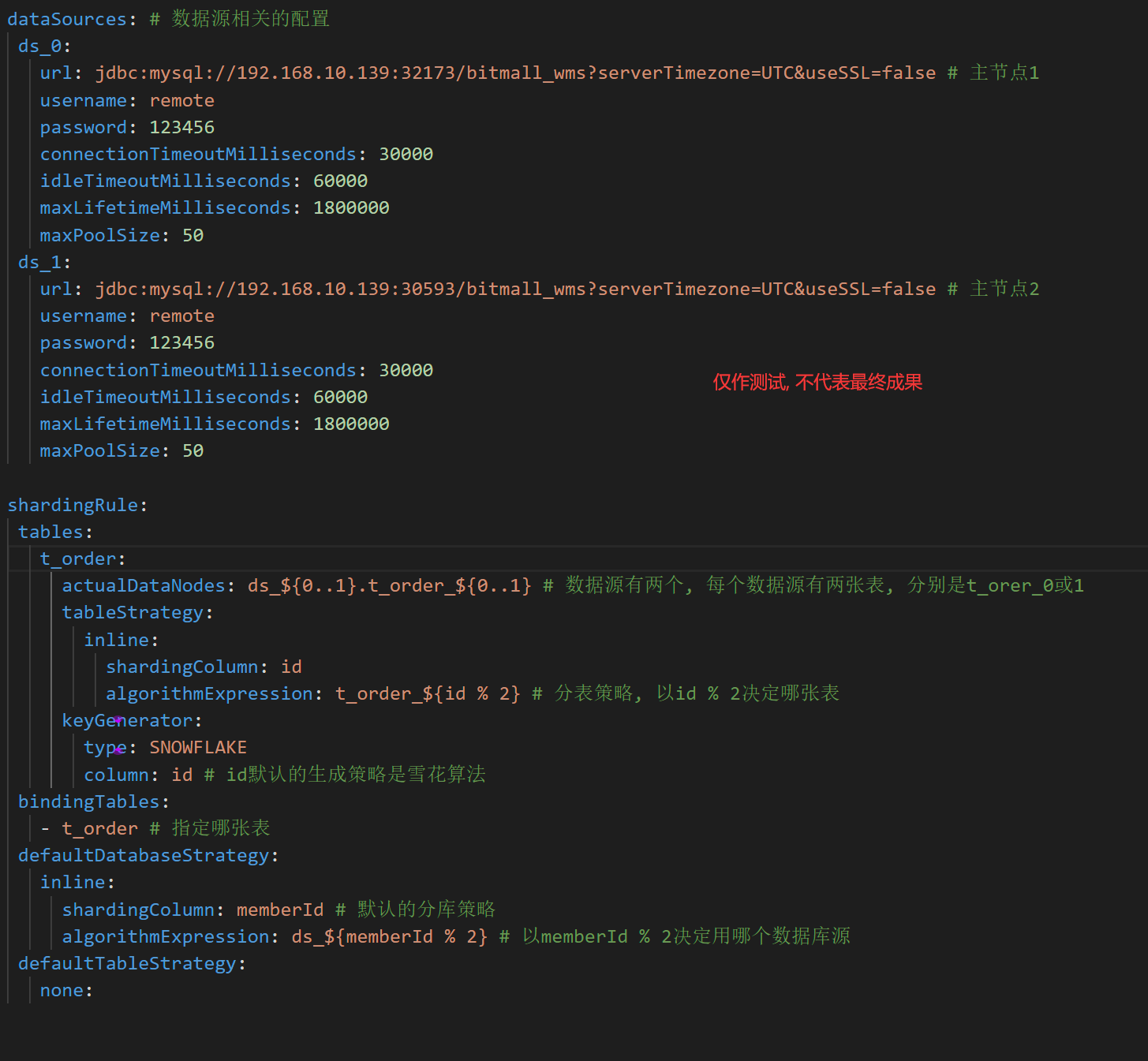
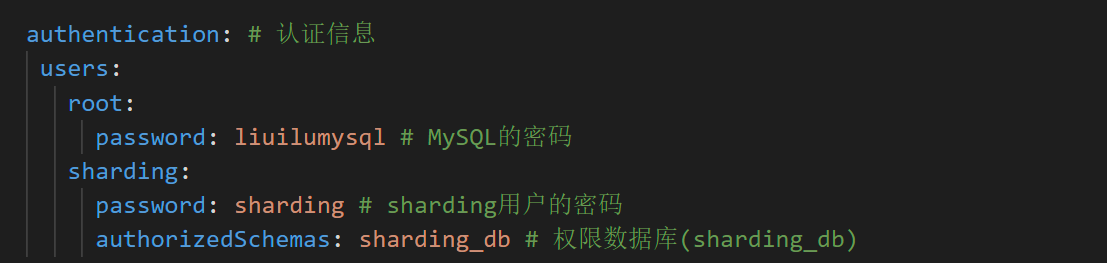
#### 启动Bug修复
1. 找不到server.yaml : 是因为没有放在纯英文目录下, 而且不能有空格
2. root用户远程连接问题: 这是因为本地的root@localhost影响了, 创建一个远程超级管理员用户就可以了
3. 没有数据库异常: ShardingSphere不会帮助我们创建数据库, 所以我们要自己在主节点中创建数据库
4. **navicat15连接shardingsphere-proxy报1064错误: 改成navicat11就好了**
5. 插入不了数据: 这里是因为我们分库分表策略用到了%, 这要求数据类型必须是int, 如果是varchar就会报错
6. 插入不了数据: 还有一种情况显示什么GROUPBY的, 这个不用管, 不影响, 是navicat的错误而已
## 分库分表的所有配置
### 1. 生成SQL的脚本文件
### 2. 配置文件

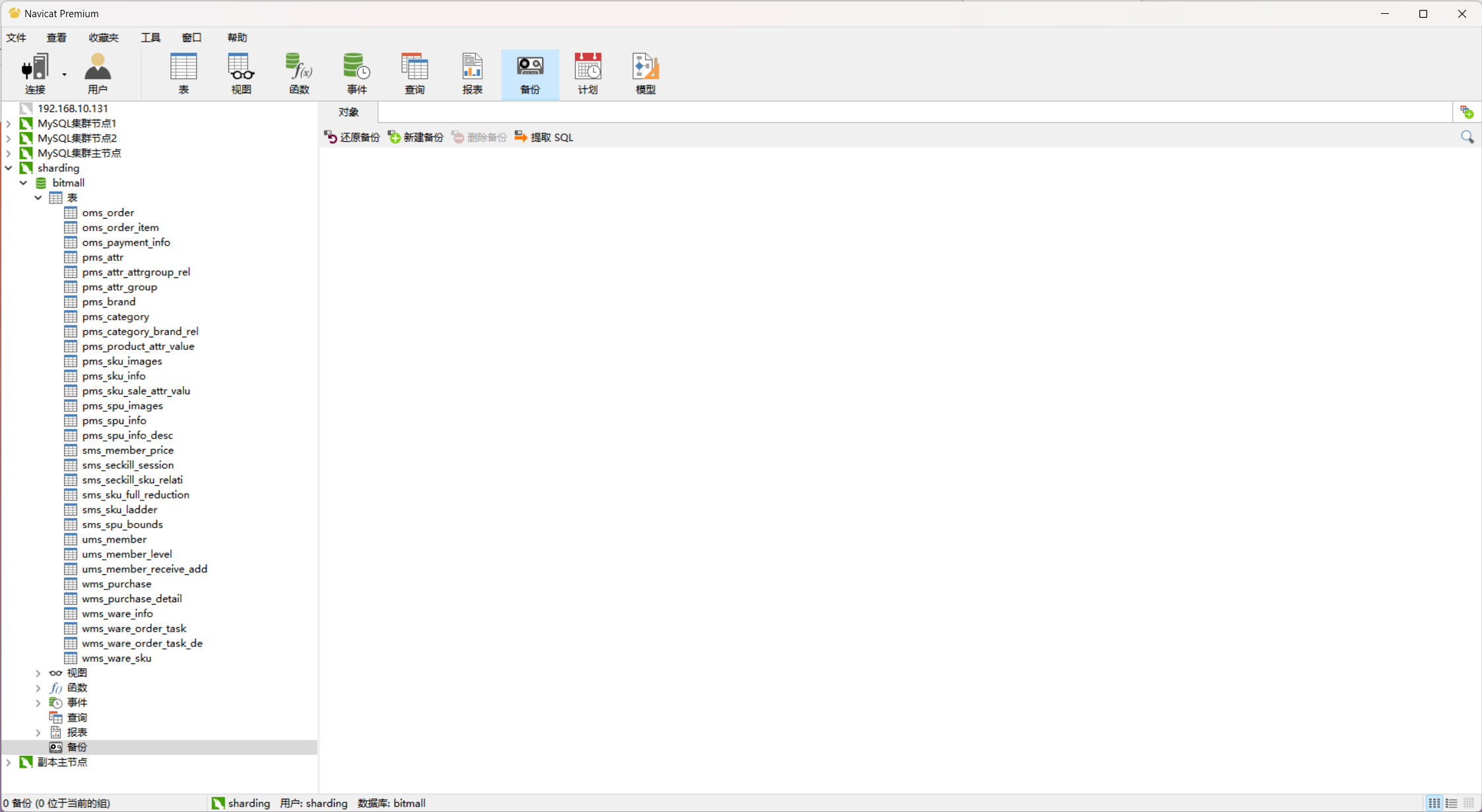
> 注意: 这个版本的navicat有问题, 他对表长限制了, 实际上是没有问题的, 我们不管就行了
### 3. 创建对应的数据库和数据表
### 4. 改成域名访问形式
> 把里面的ip地址全部改成域名就行
### 5. 创建镜像
```dockerfile
docker build -t [镜像名字, 按照阿里云] -f Dockerfile .
```
```dockerfile
# 基于centos镜像
FROM apache/sharding-proxy:4.1.0
# 添加作者
LABEL org.opencontainers.image.authors="江骏杰"
ADD conf.tar.gz /opt/sharding-proxy/
ADD mysql-connector-java-5.1.49.jar /opt/sharding-proxy/ext-lib
# 暴露端口号
EXPOSE 3307
```
### 第一个大坑
#### 是否支持多个config-sharding.yaml
#### 主从同步问题
> 因为我配置文件写错了, 所以无法主从同步bitmall_ums(配置文件写成了btimall_ums)
> 我们可以先改config_map里面的数据, 然后删除容器, 再执行以下指令即可
```shell
stop slave;
set GLOBAL SQL_SLAVE_SKIP_COUNTER=1;
start slave;
```
### 镜像地址
> 不想搞这么多, 直接拉我的镜像, 改改里面的某个配置就行
```shell
docker pull registry.cn-hangzhou.aliyuncs.com/junjie-joelib/junjie-shardingsphere-proxy
```
### kubeSphere设置镜像仓库并部署
[教程](https://v3-1.docs.kubesphere.io/zh/docs/project-user-guide/configuration/image-registry/)

// 连接问题 -> 画图 -> 部署 -> 测试
### 相关知识点
#### 为什么不可以用自增主键?
> 因为ShardingSphere-Proxy可以理解为一个逻辑数据库管理系统, 里面有逻辑数据库和逻辑表, 就以逻辑表为例, 当我们往这些表插入数据的时候, 实际上是往分库分表的目的MySQL里面插入, 如果用自增主键, 分表的情况下, 逻辑表会出现两个主键相同的数据, 不符合逻辑, 因此, 不能用自增主键
> 我们建议使用雪花算法生成主键, 而且主键建议只用BIGINT类型, 便于分库分表
#### 为什么分库分表策略要一样?
> 这里说的比较笼统, 具体的指的是两个具有关联关系的表, 它们的分库分表策略要一样, 比如说订单表和订单详情表, 它们都要以订单号作为分库分表策略, 这里主要有两个原因
> 1. 因为它们有关联关系, 所以为了逻辑上的合法性, 因此策略要一样
> 2. 因为它们有关联关系, 如果策略一样就会分配到同一个数据库上, 关联查询更快, 不需要跨数据源