K-中心点聚类算法(K-Medoide)
K-中心点算法也是一种常用的聚类算法,K-中心点聚类的基本思想和K-Means的思想相同,实质上是对K-means算法的优化和改进。在K-means中,异常数据对其的算法过程会有较大的影响。在K-means算法执行过程中,可以通过随机的方式选择初始质心,也只有初始时通过随机方式产生的质心才是实际需要聚簇集合的中心点,而后面通过不断迭代产生的新的质心很可能并不是在聚簇中的点。如果某些异常点距离质心相对较大时,很可能导致重新计算得到的质心偏离了聚簇的真实中心。
**算法步骤:**
1. 确定聚类的个数K。
2. 在所有数据集合中选择K个点作为各个聚簇的中心点。
3. 计算其余所有点到K个中心点的距离,并把每个点到K个中心点最短的聚簇作为自己所属的聚簇。
4. 在每个聚簇中按照顺序依次选取点,**计算该点到当前聚簇中所有点距离之和**,最终距离之和最小的点,则视为新的中心点。
5. 重复(2),(3)步骤,直到各个聚簇的中心点不再改变。
**如果以样本数据{A,B,C,D,E,F}为例,期望聚类的K值为2,则步骤如下:**
1. 在样本数据中随机选择B、E作为中心点。
2. 如果通过计算得到D,F到B的距离最近,A,C到E的距离最近,则B,D,F为聚簇C1,A,C,E为聚簇C2。
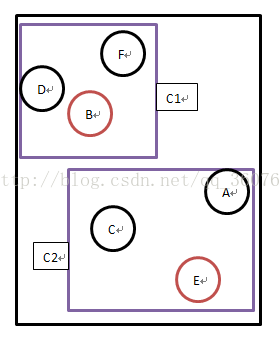
3. 在C1和C2两个聚类集合中,计算一个点到其他点的距离之和的最小值作为新的中心点,假如分别计算出D到C1中其他所有点的距离之和最小,E到C2中其他所有点的距离之和最小。
4. 再以D,E作为聚簇的中心点,重复上述步骤,直到中心点不再改变。
K-中心聚类算法计算的是某点到其它所有点的距离之和最小的点,通过距离之和最短的计算方式可以**减少某些孤立数据对聚类过程的影响**。从而使得最终效果更接近真实划分,但是由于上述过程的计算量相对K-means,大约**增加O(n)的计算量**,因此一般情况下K-中心算法更加**适合小规模数据运算。**
---
转载:[K-中心点聚类算法(K-Medoide)](https://blog.csdn.net/qq_36076233/article/details/72991055)