数据转换
# 数据转换
**数据转换的方式有:**
- 数据归一化(MinMaxScaler);
- 标准化(StandardScaler);
- 对数变换(log1p);
- 转换数据类型(astype);
- 独热编码(OneHotEncoder);
- 标签编码(LabelEncoder);
- 修复偏斜特征(box-cox)等。
---
## 1 标准化/归一化
**标准化/归一化的好处:**
- **提升模型精度**
在机器学习算法的目标函数(例如SVM的RBF内核或线性模型的l1和l2正则化),许多学习算法中目标函数的基础都是假设所有的特征都是零均值并且具有同一阶数上的方差。如果某个特征的方差比其他特征大几个数量级,那么它就会在学习算法中占据主导位置,导致学习器并不能像我们说期望的那样,从其他特征中学习。
举一个简单的例子,在KNN中,我们需要计算待分类点与所有实例点的距离。假设每个实例点(instance)由n个features构成。如果我们选用的距离度量为欧式距离,如果数据预先没有经过归一化,那么那些绝对值大的features在欧式距离计算的时候起了决定性作用。
从经验上说,归一化是让不同维度之间的特征在数值上有一定比较性,可以大大提高分类器的准确性。
- **提升收敛速度**
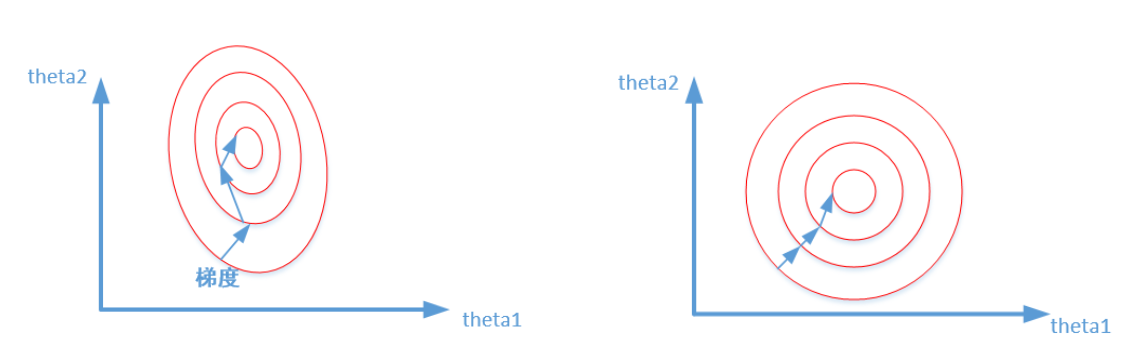
**对于线性模型来说**,数据归一化后,最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解。
比较这两个图,前者是没有经过归一化的,在梯度下降的过程中,走的路径更加的曲折,而第二个图明显路径更加平缓,收敛速度更快。 对于神经网络模型,避免饱和是一个需要考虑的因素,通常参数的选择决定于input数据的大小范围。
[**归一化与标准化的区别:**](https://blog.csdn.net/u010947534/article/details/86632819)
归一化: $\frac{x_{i}-\min \left(x_{i}\right)}{\max \left(x_{i}\right)-\min \left(x_{i}\right)}$
标准化:$\frac{x_{i}-\bar{x}}{s d(x)}$
**首先明确,在机器学习中,标准化是更常用的手段**,归一化的应用场景是有限的。我总结原因有两点:
* **1、标准化更好保持了样本间距。**
当样本中有异常点时,归一化有可能将正常的样本“挤”到一起去。比如三个样本,某个特征的值为1,2,10000,假设10000这个值是异常值,用归一化的方法后,正常的1,2就会被“挤”到一起去。如果不幸的是1和2的分类标签还是相反的,那么,当我们用梯度下降来做分类模型训练时,模型会需要更长的时间收敛,因为将样本分开需要更大的努力!而标准化在这方面就做得很好,至少它不会将样本“挤到一起”。
* **2、标准化更符合统计学假设**
对一个数值特征来说,很大可能它是服从正态分布的。标准化其实是基于这个隐含假设,只不过是略施小技,将这个正态分布调整为均值为0,方差为1的标准正态分布而已。
哪些模型必须归一化/标准化:SVM、KNN、神经网络、PCA等
> 所有涉及到距离的都需要标准化:KNN,PCA,SVM,deep learning
不涉及距离的则不需要标准化:树模型,linear regression,logistic regression
---
## 2 各编码之间的区别:
#### 独热编码:

#### 哑变量编码:

#### 标签编码:
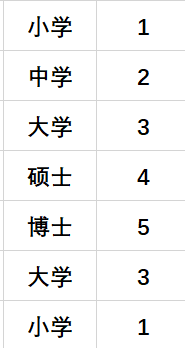
独热编码缺点就是,当类别的数量很多时,特征空间会变得非常大。
中学和硕士的平均值是大学,所以label encoding最直观的缺点就是赋值难以解释,适用场景更窄。
独热编码与哑变量编码使用场景区分在于加不加bias项(偏置项$β_0$):
> **总结**:我们使用one-hot编码时,通常我们的模型不加bias项 或者 加上bias项然后使用正则化手段去约束参数;当我们使用哑变量编码时,通常我们的模型都会加bias项,因为不加bias项会导致固有属性的丢失。
[离散型特征编码方式:one-hot与哑变量](https://www.cnblogs.com/lianyingteng/p/7792693.html)
此外还有高级版本的编码方式:
#### 均值编码(mean encoding)
[均值编码](https://www.jianshu.com/p/35d199b47ca4),它有很多名字,例如:likelihood encoding、target encoding,它是针对高基数类别特征的有监督编码。当一个类别特征列包括了极多不同类别时(如家庭地址,动辄上万个类别时),可以采用。
优点:和独热编码相比,节省内存、减少算法计算时间、有效增强模型表现。
## 3 修复偏斜特征:
**BOX-COX转换**
我们测得一些数据,要对数据进行分析的时候,会发现数据有一些问题使得我们不能满足我们以前分析方法的一些要求(正态分布、平稳性)为了满足经典线性模型的正态性假设,常常需要使用指数变换或者对数转化,使其转换后的数据接近正态。
> **优势**:
线性回归模型满足线性性、独立性、方差齐性以及正态性的同时,又不丢失信息,此种变换称之为Box—Cox变换。
误差与y相关,不服从正态分布,于是给线性回归的最小二乘估计系数的结果带来误差。
使用Box-Cox变换族一般都可以保证将数据进行成功的正态变换,但在二分变量或较少水平的等级变量的情况下,不能成功进行转换,此时,我们可以考虑使用广义线性模型,如LOGUSTICS模型、Johnson转换等。
Box-Cox变换后,残差可以更好的满足正态性、独立性等假设前提,降低了伪回归的概率
**BOX-COX变换的目标有两个:**
**1、** 变换后,可以一定程度上减小不可观测的误差和预测变量的相关性。**主要操作是对因变量转换**,使得变换后的因变量于回归自变量具有线性相依关系,误差也服从正态分布,误差各分量是等方差且相互独立。
**2、** 用这个变换来使得因变量获得一些性质,比如在时间序列分析中的平稳性,或者使得因变量分布为正态分布。
关于box-cox转换,一般是用于连续的变量不满足正态的时候,在做线性回归的过程中,一般线性模型假定:
$$Y=X \beta+\varepsilon$$
其中ε假设满足正态分布,正态分布的假设让回归曲线对于极端值更加敏感:因为在正态假设下,极大的误差看起来是很不可能的,所以当极大的误差出现时,回归曲线往往会偏向极端点。
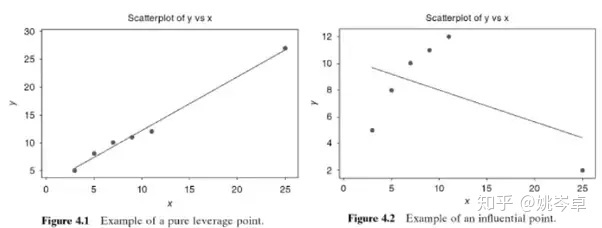
这时正态假设在某些情况下可能会限制线性回归的表现
因此,很多时候利用实际数据建立回归模型时,个别变量的系数通不过。例如往往不可观测的误差 ε 可能是和预测变量相关的,不服从正态分布,于是给线性回归的最小二乘估计系数的结果带来误差,为了使模型满足线性性、独立性、方差齐性以及正态性,需改变数据形式,故应用BOX-COX转换。具体详情这里不做过多介绍,当然还有很多转换非正态数据分布的方式:
- 对数转换:$y_{i}=\ln \left(x_{i}\right)$
- 平方根转换:$y_{i}=\sqrt{x}_{i}$
- 倒数转换:$y_{i}=1 / x_{i}$
- 平方根后取倒数:$y_{i}=1 / \sqrt{x}_{i}$
- 平方根后再取反正弦:$y_{i}=\arcsin \left(\sqrt{x}_{i}\right)$
- 幂转换:$y_{i}=\left(x_{i}^{\lambda}-1\right) /\left(\tilde{x}^{\lambda+1}\right)$
其中 $\tilde{x}=\left(\prod_{i=1}^{n} x_{i}\right)^{\frac{1}{n}},$ 参数 $\lambda \in[-1.5,1]$
在一些情况下(P值<0.003)上述方法很难实现正态化处理,所以优先使用BOX-COX转换,但是当P值>0.003时两种方法均可,优先考虑普通的平方变换。(注:统计学上一般P值大于0.05我们可认为该组数据是符合正态分布。)
BOX-COX的变换公式:$y^{(\lambda)}=\left\{\begin{array}{l}\frac{(y+c)^{\lambda}-1}{\lambda}, \text { if } \lambda \neq 0 \\ \log (y+c), \text { if } \lambda=0\end{array}\right.$
具体实现:
```python
from scipy.stats import boxcox
boxcox_transformed_data = boxcox(original_data)
```