DBSCAN
DBSCAN是一种非常著名的**基于密度的聚类算法**。其英文全称是 Density-Based Spatial Clustering of Applications with Noise,意即:**一种基于密度,对噪声鲁棒的空间聚类算法**。
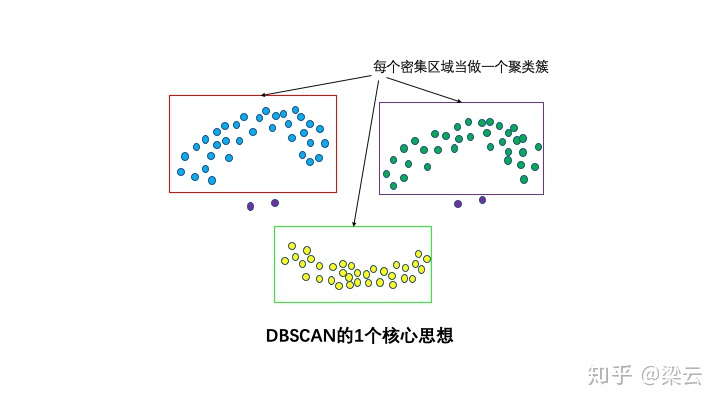
直观效果上看,DBSCAN算法可以找到样本点的全部密集区域,并把这些密集区域当做一个一个的聚类簇。
## 1 基本概念
**DBSCAN的基本概念可以用1,3,3,4来总结。**
**1个核心思想:基于密度**
直观效果上看,DBSCAN算法可以找到样本点的全部密集区域,并把这些密集区域当做一个一个的聚类簇。
::: hljs-center
:::
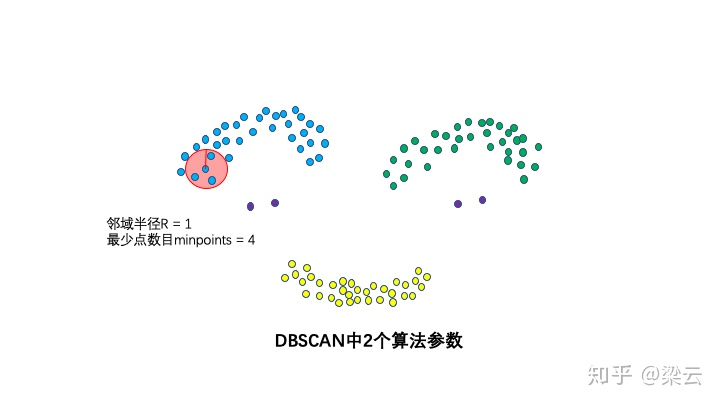
**3个算法参数:邻域半径R、最少点数目min_points和所选择的距离度量(比如欧几里得或曼哈顿距离)**
这两个算法参数实际可以刻画什么叫密集——当邻域半径R内的点的个数大于最少点数目minpoints时,就是密集。
::: hljs-center
:::
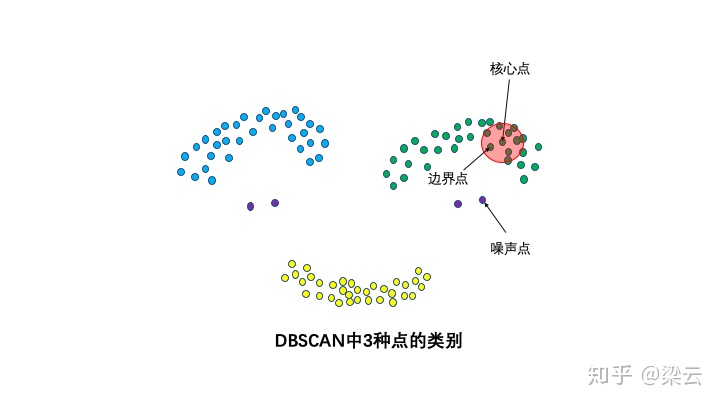
**3种点的类别:核心点,边界点和噪声点**
邻域半径R内样本点的数量大于等于min_points的点叫做核心点。不属于核心点但在某个核心点的邻域内的点叫做边界点。既不是核心点也不是边界点的是噪声点。
::: hljs-center
:::
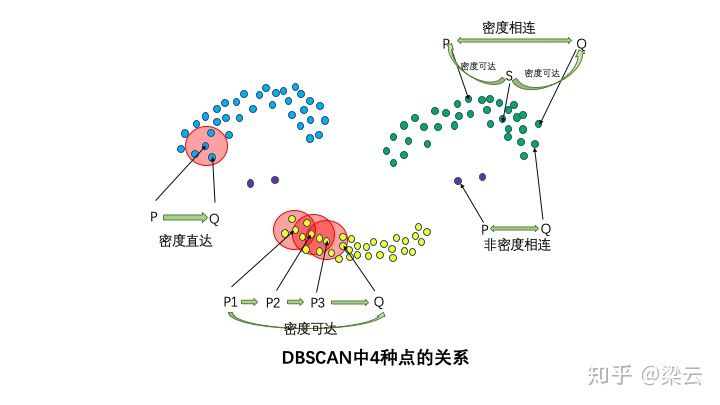
**4种点的关系:密度直达,密度可达,密度相连,非密度相连**
如果P为核心点,Q在P的R邻域内,那么称P到Q密度直达。任何核心点到其自身密度直达,密度直达不具有对称性,如果P到Q密度直达,那么Q到P不一定密度直达。
如果存在核心点P2,P3,……,Pn,且P1到P2密度直达,P2到P3密度直达,……,P(n-1)到Pn密度直达,Pn到Q密度直达,则P1到Q密度可达。密度可达也不具有对称性。
如果存在核心点S,使得S到P和Q都密度可达,则P和Q密度相连。密度相连具有对称性,如果P和Q密度相连,那么Q和P也一定密度相连。密度相连的两个点属于同一个聚类簇。
如果两个点不属于密度相连关系,则两个点非密度相连。非密度相连的两个点属于不同的聚类簇,或者其中存在噪声点。
::: hljs-center
:::
## 2 DBSCAN算法步骤
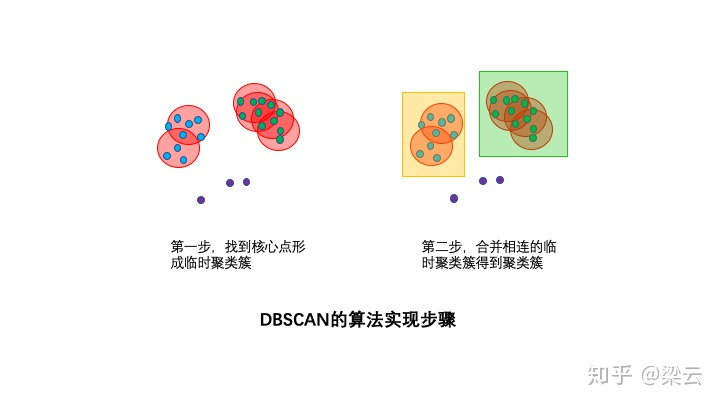
DBSCAN的算法步骤分成两步。
1. **寻找核心点形成临时聚类簇**
扫描全部样本点,如果某个样本点R半径范围内点数目>=MinPoints,则将其纳入核心点列表,并将其密度直达的点形成对应的临时聚类簇。
2. **合并临时聚类簇得到聚类簇**
对于每一个临时聚类簇,检查其中的点是否也为一个核心点,如果是,将该点对应的临时聚类簇和当前临时聚类簇合并,得到新的临时聚类簇。
重复此操作,直到当前临时聚类簇中的每一个点要么不在核心点列表,要么其密度直达的点都已经在该临时聚类簇,该临时聚类簇升级成为聚类簇。
继续对剩余的临时聚类簇进行相同的合并操作,直到全部临时聚类簇被处理。
::: hljs-center
:::
## 3 参数选择
**DBSCAN聚类使用到一个$k$-距离的概念**, $k$-距离是指:给定数据集$P=\{p(i);i=0,1,...,n\}$,对于任意点$P(i)$,计算点$P(i)$到集合$D$的子集$S=\{p(1), p(2), ..., p(i-1), p(i+ 1), ... ,p(n)\}$中所有点之间的距离,距离按照从小到大的顺序排序,假设排序后的距离集合为$D= \{d(1), d(2), .... ,d(k-1),d(k), d(k+1),...,d(n)\}$..则$d(k)$就被称为$k$-距离。也就是说,$k$距离是点$p(i)$到所有点 (除了$p(i)$点本身) 之间距离第$k$近的距离。对待聚类集合中每个点$p(i)$都计算$k$距离,后得到所有点的$k$-距离集合$E=\{e(1), e(2), .... ,e(n)\}$。
**邻域半径R**:根据得到的所有点的$k$距离集合$E$,对集合$E$进行升序排序后得到$k$-距集合$E'$,需要拟合一条排序后的$E'$集合中$k$-距离的变化曲线图, 然后绘出曲线,通过观察,将**急剧发生变化的位置**所对应的邻域半径$k$距离的值,确定为邻域半径R的值。
**最少点数目min_points**:确定min_points的大小,实际地是确定$k$-距离中$k$的值,DBSCAN算法取$k$=4,则min_points=4。一般取的小一些,多次尝试。
此外,如果觉得经验值聚类的结果不满意,可以适当调整R和min_points的值, 经过多次迭代计算对比,选择最合适的参数值。
可以看出,如果min_points不变, R取得值过大,导致大多数都聚到同一个簇中;R过小,会导致已一个簇的分裂。
如果R不变, min_pointss的值取得过大,会导致同一个簇中点被标记为噪声点;min_points过小,会导致发现大量的核心点。
## 4 DBSCAN优缺点
>**优点:**
>1. 聚类**速度快**且能够有效处理噪声点和发现任意形状的空间聚类;
>2. 与K-MEANS比较起来,**不需要输入要划分的聚类个数**;
>3. 聚类簇的形状没有偏倚;
>4. **对远离密度核心的噪声点鲁棒**
>
>**缺点:**
>1. 当**数据量增大时**,要求较大的内存支持I/O消耗也很大;
>2. **当空间聚类的密度不均匀、聚类间距差相差很大时,聚类质量较差**,因为这种情况下参数MinPts和Eps选取困难。
>3. 算法聚类效果依赖于距离公式选取,实际应用中常用欧式距离,**对于高维数据,存在“维数灾难”。**
## 5 DBSCAN使用范例
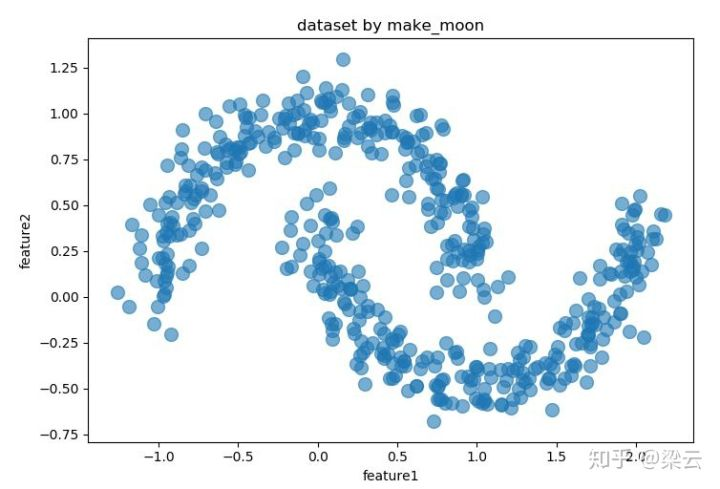
- **生成样本点**
```python
import numpy as np
import pandas as pd
from sklearn import datasets
%matplotlib inline
X,_ = datasets.make_moons(500,noise = 0.1,random_state=1)
df = pd.DataFrame(X,columns = ['feature1','feature2'])
df.plot.scatter('feature1','feature2', s = 100,alpha = 0.6, title = 'dataset by make_moon')
```
::: hljs-center
:::
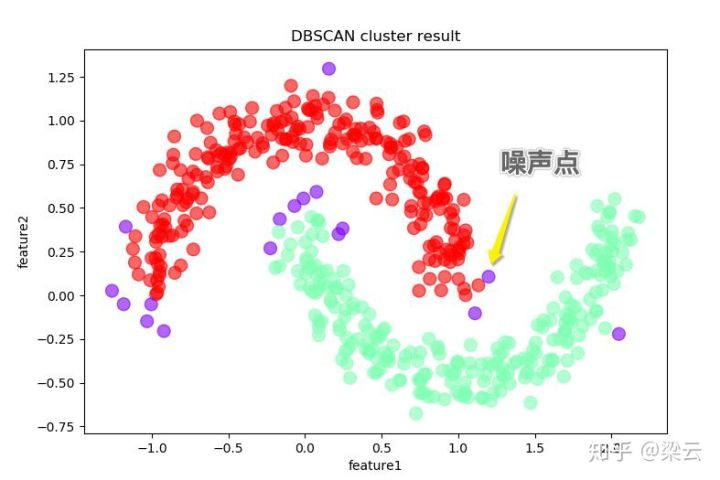
- **调用dbscan接口完成聚类**
```python
from sklearn.cluster import dbscan
# eps为邻域半径,min_samples为最少点数目
core_samples,cluster_ids = dbscan(X, eps = 0.2, min_samples=20)
# cluster_ids中-1表示对应的点为噪声点
df = pd.DataFrame(np.c_[X,cluster_ids],columns = ['feature1','feature2','cluster_id'])
df['cluster_id'] = df['cluster_id'].astype('i2')
df.plot.scatter('feature1','feature2', s = 100,
c = list(df['cluster_id']),cmap = 'rainbow',colorbar = False,
alpha = 0.6,title = 'DBSCAN cluster result')
```
::: hljs-center
:::