GBDT+LR
# GBDT构建新的特征思想
特征决定模型性能上界,例如深度学习方法也是将数据如何更好的表达为特征。如果能够将数据表达成为线性可分的数据,那么使用简单的线性模型就可以取得很好的效果。GBDT构建新的特征也是使特征更好地表达数据。
主要参考Facebook[1],原文提升效果:
>在预测Facebook广告点击中,使用一种将决策树与逻辑回归结合在一起的模型,其优于其他方法,超过3%。
**主要思想:GBDT每棵树的路径直接作为LR输入特征使用。**
>用已有特征训练GBDT模型,然后利用GBDT模型学习到的树来构造新特征,最后把这些新特征加入原有特征一起训练模型。构造的新特征向量是取值0/1的,向量的每个元素对应于GBDT模型中树的**叶子结点**。当一个样本点通过某棵树最终落在这棵树的一个叶子结点上,那么在新特征向量中这个叶子结点对应的元素值为1,而这棵树的其他叶子结点对应的元素值为0。新特征向量的长度等于GBDT模型里所有树包含的叶子结点数之和。
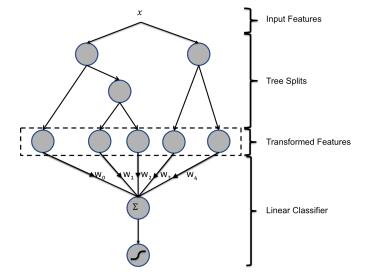
>上图为混合模型结构。输入特征通过增强的决策树进行转换。 每个单独树的输出被视为稀疏线性分类器的分类输入特征。 增强的决策树被证明是非常强大的特征转换。
例子1:上图有两棵树,左树有三个叶子节点,右树有两个叶子节点,最终的特征即为五维的向量。对于输入x,假设他落在左树第一个节点,编码[1,0,0],落在右树第二个节点则编码[0,1],所以整体的编码为[1,0,0,0,1],这类编码作为特征,输入到线性分类模型(LR or FM)中进行分类。
论文中GBDT的参数,树的数量最多500颗(500以上就没有提升了),每棵树的节点不多于12。
# GBDT与LR融合方案
在CTR预估中,如何利用AD ID是一个问题。
直接将AD ID作为特征建树不可行,而onehot编码过于稀疏,为每个AD ID建GBDT树,相当于发掘出区分每个广告的特征。而对于曝光不充分的样本即长尾部分,无法单独建树。
综合方案为:使用GBDT对非ID和ID分别建一类树。
**非ID类树:**
不以细粒度的ID建树,此类树作为base,即这些ID一起构建GBDT。即便曝光少的广告、广告主,仍可以通过此类树得到有区分性的特征、特征组合。
**ID类树:**
以细粒度 的ID建一类树(每个ID构建GBDT),用于发现曝光充分的ID对应有区分性的特征、特征组合。如何根据GBDT建的两类树,对原始特征进行映射?以如下图3为例,当一条样本x进来之后,遍历两类树到叶子节点,得到的特征作为LR的输入。当AD曝光不充分不足以训练树时,其它树恰好作为补充。
**方案如图:**
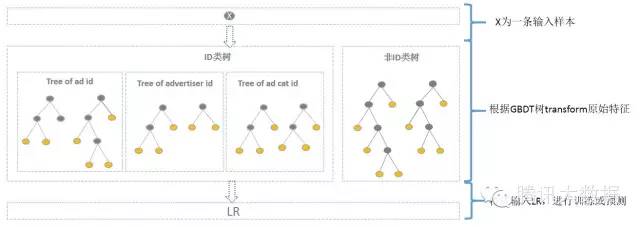
其中kaggle竞赛一般树的数目最多为30,通过GBDT转换得到特征空间相比于原始ID低了很多
# Python实现
核心代码如下:其中关键方法为树模型(GBDT)的[apply()](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingClassifier.html#sklearn.ensemble.GradientBoostingClassifier.apply)方法。
```python
# 弱分类器的数目
n_estimator = 10
# 随机生成分类数据。
X, y = make_classification(n_samples=80000)
# 切分为测试集和训练集,比例0.5
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5)
# 将训练集切分为两部分,一部分用于训练GBDT模型,另一部分输入到训练好的GBDT模型生成GBDT特征,然后作为LR的特征。这样分成两部分是为了防止过拟合。
X_train, X_train_lr, y_train, y_train_lr = train_test_split(X_train, y_train, test_size=0.5)
# 调用GBDT分类模型。
grd = GradientBoostingClassifier(n_estimators=n_estimator)
# 调用one-hot编码。
grd_enc = OneHotEncoder()
# 调用LR分类模型。
grd_lm = LogisticRegression()
'''使用X_train训练GBDT模型,后面用此模型构造特征'''
grd.fit(X_train, y_train)
# fit one-hot编码器
grd_enc.fit(grd.apply(X_train)[:, :, 0])
'''
使用训练好的GBDT模型构建特征,然后将特征经过one-hot编码作为新的特征输入到LR模型训练。
'''
grd_lm.fit(grd_enc.transform(grd.apply(X_train_lr)[:, :, 0]), y_train_lr)
# 用训练好的LR模型多X_test做预测
y_pred_grd_lm = grd_lm.predict_proba(grd_enc.transform(grd.apply(X_test)[:, :, 0]))[:, 1]
# 根据预测结果输出
fpr_grd_lm, tpr_grd_lm, _ = roc_curve(y_test, y_pred_grd_lm)
```
这只是一个简单的demo,具体参数还需要根据具体业务情景调整。
官方例子介绍:[http://scikit-learn.org/stable/auto_examples/ensemble/plot_feature_transformation.html#example-ensemble-plot-feature-transformation-py](http://scikit-learn.org/stable/auto_examples/ensemble/plot_feature_transformation.html#example-ensemble-plot-feature-transformation-py
)
# 总结
对于样本量大的数据,线性模型具有训练速度快的特点,但线性模型学习能力限于线性可分数据,所以就需要特征工程将数据尽可能地从输入空间转换到线性可分的特征空间。GBDT与LR的融合模型,其实使用GBDT来发掘有区分度的特征以及组合特征,来替代人工组合特征
---
转载:[GBDT原理及利用GBDT构造新的特征-Python实现](https://blog.csdn.net/shine19930820/article/details/71713680#2-gbdt%E6%9E%84%E5%BB%BA%E6%96%B0%E7%9A%84%E7%89%B9%E5%BE%81%E6%80%9D%E6%83%B3)