kNN分类算法
## 1 K-近邻算法
k-近邻算法(k Nearest Neighbor),是最基本的分类算法,其基本思想是采用测量不同特征值之间的距离方法进行分类。
## 2 算法原理
存在一个样本数据集合(训练集),并且样本集中每个数据都存在标签(即每一数据与所属分类的关系已知)。输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较(计算距离),然后提取样本集中特征最相似数据(最近邻)的分类标签。一般会取前k个最相似的数据,然后取k个最相似数据中出现次数最多的标签(分类)最后新数据的分类。
因此,这是一个很“懒惰”的算法,所谓的训练数据并没有形成一个“模型”,而是一个新的数据需要分类了,去和所有训练数据逐一比较,最终给出分类。这个特征导致在数据量较大时,性能很差劲。
## 3 算法过程
对未知类别属性的数据集中的每个点依次执行以下操作:
1. 计算已知类别数据集中的点与当前点之间的距离(**欧式距离、曼哈顿距离或者余弦夹角等各种距离算法,具体情况具体分析用哪种,同K-Means**);
2. 按照距离递增次序排序;
3. 选取与当前点距离最小的k个点;
4. 确定前k个点所在类别的出现频率;
5. 返回前k个点出现频率最高的类别作为当前点的预测分类。
**欧氏距离计算:**
二维平面上两点A(x1,y1)与B(x2,y2)间的欧氏距离:
::: hljs-center
$d_{12}=\sqrt{\left(x_{1}-x_{2}\right)^{2}+\left(y_{1}-y_{2}\right)^{2}}$
:::
三维空间两点A(x1,y1,z1)与B(x2,y2,z2)间的欧氏距离:
::: hljs-center
$d_{12}=\sqrt{\left(x_{1}-x_{2}\right)^{2}+\left(y_{1}-y_{2}\right)^{2}+\left(z_{1}-z_{2}\right)^{2}}$
:::
n维空间两点的欧式距离以此类推
## 4 计算案例
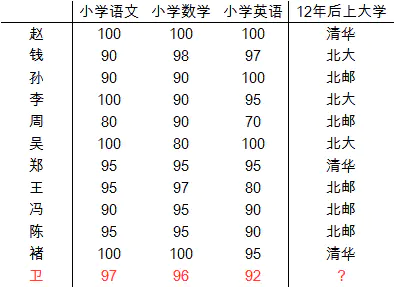
我还是瞎编一个案例,下表有11个同学的小学成绩和12年后读的大学的情况,现在已知“卫”同学的小学成绩了,可以根据KNN来预测未来读啥大学。
::: hljs-center
:::
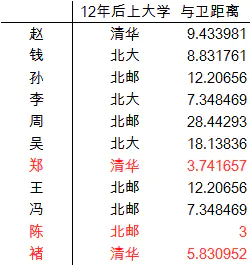
逐一计算各位同学与卫同学的距离,然后我们选定3位(即这里的k=3)最为接近的同学,推测卫同学最终的大学
::: hljs-center
:::
3位同学中2个清华,1个北邮,所以卫同学很有可能在12年后上清华。
## 5 算法要点
- **K的选择**,一般不超过训练集数量的平方根。在实际应用中,**K值一般取一个比较小的数值**,例如采用**交叉验证法**(简单来说,就是一部分样本做训练集,一部分做测试集)来选择最优的K值,以避免"过拟合"或"欠拟合"
- 距离更近的近邻也许更应该决定最终的分类,所以可以对于K个近邻根据距离的大小**设置权重**,结果会更有说服力
- 如果采用欧氏距离计算,不同变量间的值域差距较大时,需要进行**标准化**,否则值域较大的变量将成为最终分类的唯一决定因素
---
转载:[最“懒惰”的kNN分类算法](https://www.jianshu.com/p/2de0fd5b66e7)
参考:[KNN中的k如何选择?](https://blog.csdn.net/weixin_42234472/article/details/85062142)