随机森林
**核心:决策树+两个随机(数据样本+特征)**
## 1 算法内容
随机森林借鉴了**集思广益**的思想,是一种集成学习的方法,预测时建立多棵**CART决策树**,再综合判断(分类:最大投票;回归:取均值。如图所示)。为了增强其泛化能力,在选取基学习器训练集和结点特征选择时加入随机性。
::: hljs-center
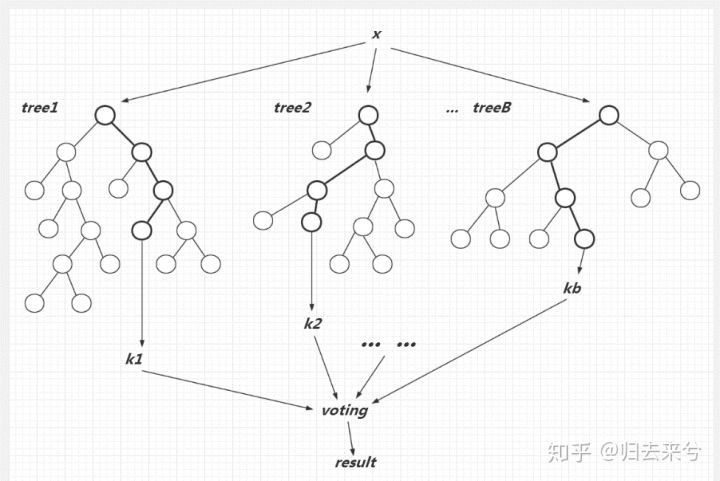
:::
1. **基学习训练集选取**
对每个待训练的基学习器 $T_i(i=1,2,3,...,n)$ ,$n$为基学习器数量, 在原训练集$X$中,逐一有放回地**随机抽取$m$个样本**(一般和原训练集样本量一致),共进行$n$轮抽样,将各轮抽出的样本集分别作为各个基学习器的训练集。
2. **结点特征选择**
传统决策树在选择划分属性时是在当前结点的属性集合中(假设共有$d$个结点)基于信息纯度准则(最大信息增益、最大信息增益率、最小基尼指数)选择一个最优属性,**而在随机森林中**,对基决策树的每个结点,先从该结点的属性集合中**随机选择一个包含$k$个属性的子集**,再对该子集进行基于信息准则的划分属性选择。这里的$k$控制了随机性的引入程度;若令$k=d$,则基决策树的构建与传统决策树相同;若令$k=1$,则每次的属性选择纯属随机,与信息准则无关;一般情况下,推荐 $k=log_2d$ 。
3. **关于调参**
- 如何选取$k$,可以考虑有$d$个属性,取 $k=\sqrt{d}$ ;
- 最大深度(不超过8层)
- 棵数
- 最小分裂样本数
- 类别比例
## 2 算法描述

输入:样本集 $D=\left\{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \ldots,\left(x_{m}, y_{m}\right)\right\}$ ,弱分类器迭代次数$n$。
输出:强学习器$f(x)$。
>1) 对于$i=1,2...,n$:
>
> a) 对训练集进行第$i$次**有抽样放回**的方法,得到包含$m$个样本的采样集 $D_i$ ;
>
> b) 用采样集 $D_i$ 训练第$i$个决策树模型 $T_i(x)$ ,在训练决策树模型的节点的时候, 在节点上所有的样本特征中<font color=Blue>**不重复的随机选择**</font>k个样本特征, 在这随机选择的k个特征中选择最优的特征来做决策树的左右子树划分,建立CART决策树。
>
>2) **如果是分类算法预测**,则$n$个弱学习器投出最多票数的类别或者类别之一为最终类别。**如果是回归算法**,$n$个弱学习器得到的回归结果进行算术平均得到的值为最终的模型输出。
# 3、常问问题
## 随机森林如何处理缺失值?
根据随机森林创建和训练的特点,随机森林对缺失值的处理还是比较特殊的。
首先,给缺失值预设一些估计值,比如数值型特征,选择其余数据的中位数或众数作为当前的估计值
然后,根据估计的数值,建立随机森林,把所有的数据放进随机森林里面跑一遍。记录每一组数据在决策树中一步一步分类的路径.
判断哪组数据和缺失数据路径最相似,引入一个相似度矩阵,来记录数据之间的相似度,比如有N组数据,相似度矩阵大小就是N*N
如果缺失值是类别变量,通过权重投票得到新估计值,如果是数值型变量,通过加权平均得到新的估计值,如此迭代,直到得到稳定的估计值。
其实,该缺失值填补过程类似于推荐系统中采用协同过滤进行评分预测,先计算缺失特征与其他特征的相似度,再加权得到缺失值的估计,而随机森林中计算相似度的方法(数据在决策树中一步一步分类的路径)乃其独特之处。
这个补缺失值的思想和KNN有些类似。
> **解释相似度矩阵**:
相似度矩阵就是任意两个观测实例间的相似度矩阵,原理是如果两个观测实例落在同一棵树的相同节点次数越多,则这两个观测实例的相似度越高。
> 详细来说:
Proximity 用来衡量两个样本之间的相似性。原理就是如果两个样本落在树的同一个叶子节点的次数越多,则这两个样本的相似度越高。当一棵树生成后,让数据集通过这棵树,落在同一个叶子节点的”样本对(xi,xj)” proximity 值 P(i,j) 加 1 。所有的树生成之后,利用树的数量来归一化 proximity matrix。继而,我们得到缺失值所在样本的权重值,权重值相近的可以用于缺失值的填补参考。
# 过拟合问题
你已经建了一个有10000棵树的随机森林模型。在得到0.00的训练误差后,你非常高兴。但是,验证错误是34.23。到底是怎么回事?你还没有训练好你的模型吗?
答:该模型过度拟合,因此,为了避免这些情况,我们要用交叉验证来调整树的数量。但其实树的深度更影响过过拟合,树的数量感觉是在减少方差。
## 随机森林分类效果的影响因素
- 森林中任意两棵树的相关性:相关性越大,错误率越大;
- 森林中每棵树的分类能力:每棵树的分类能力越强,整个森林的错误率越低。
减小特征选择个数m,树的相关性和分类能力也会相应的降低;增大m,两者也会随之增大。所以关键问题是如何选择最优的m(或者是范围)。
---
转载:
[数据分析面试【机器学习】总结之-----bagging和随机森林常见面试题整理](https://blog.csdn.net/qq_34069667/article/details/107834490)