缺失值处理
建议:不同场景下的数据缺失机制不同,这需要工程师基于对业务选择合适的填充方法。
[如何判断缺失值类型?](https://zhuanlan.zhihu.com/p/138628034)
缺失值的分类按照数据缺失机制可分为:
**可忽略的缺失**
> - **完全随机缺失**(missing completely at random, MCAR),所缺失的数据发生的概率既与已观察到的数据无关,也与未观察到的数据无关
>*(例如,由于测量设备出故障导致某些值缺失)*
> - **随机缺失**(missing at random, MAR),假设缺失数据发生的概率与所观察到的变量是有关的,而与未观察到的数据的特征是无关的。
*(例如,人们是否透露收入可能与性别、教育程度、职业等因素有关系)*
**不可忽略的缺失**
> - **非随机缺失**(missing not at random, MNAR),如果不完全变量中数据的缺失既依赖于完全变量又依赖于不完全变量本身,这种缺失即为不可忽略的缺失。
*(例如,在控制了性别、教育程度、职业等已观测因素之后,如果收入是否缺失还依赖于收入本身的值,那么收入就是非随机缺失的*)
平常工作中遇到的缺失值大部分情况下是随机的(缺失变量和其他变量有关)
这个就可以用estimator来做了,选其中一个变量(y),然后用其他变量作为X,随便选个值填充X的缺失部分,用 X 训练一个模型,再预测 y 的缺失部分(大致思路)
此外有些数据是符合某种分布的,利用这个分布呢也可以填充缺失的数据,如(EM算法)
-----
**处理缺失数据的三个标准:**
**1. 非偏置的参数估计**
不管你估计means, regressions或者是odds ratios,都希望参数估计可以准确代表真实的总体参数。在统计项中,这意味着估计需要是无偏的。有缺失值可能会影响无偏估计,所以需要处理。
**2. 有效的能力:**
删除缺失数据会降低采样的大小,因此会降低power。如果说问题是无偏的,那么得到的结果会是显著的,那么会有足够的能力来检验这个效力(have adequate power to detect your effects)。反之,整个检测可能失效。
**3. 准确的标准差(影响p值和置信区间):**
不仅需要参数估计无偏,还需要标准差估计准确,在统计推断中才会有效。
-----
# 数据缺失的处理方法
缺失值处理的方法大致分为这几类:1、删除法;2、基于插补的方法;3、基于模型的方法; 4、不处理; 5、映射高维
有些处理方法是基于完全随机缺失假设(MCAR),一般来说,当数据不是 MCAR 而 是随机缺失(MAR)时,这些方法是不适用的;而有些方法(如似然估计法)在 MAR 的假设下是适用的,因此,在进行缺失数据处理时,首先需要认真分析缺失数 据产生的原因,然后采取有针对性的补救措施,这样才能够获得无偏或弱偏估计。
----
**此处关于使用多重插补来处理非随机缺失(MNAR)的问题,它其实效果不一定,也可能出现效果倒退的情况,总的说多重更适合MAR**
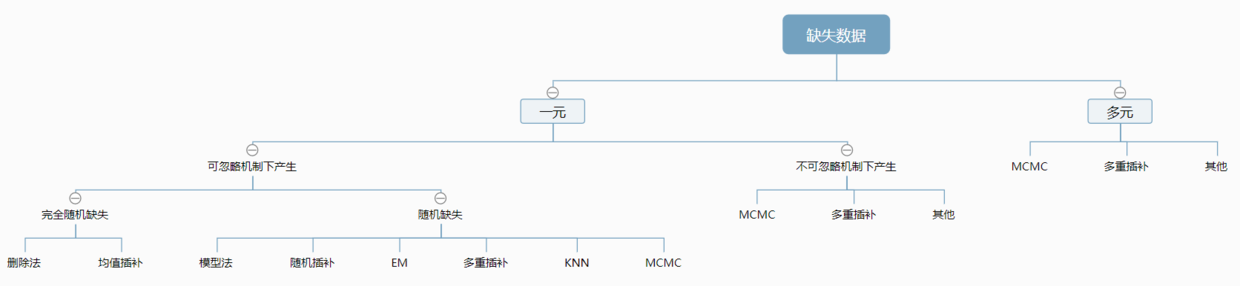
注:此处一元与多元指的是仅有一个特征有缺失值与多个特征有缺失值
对于不同类别的缺失值的处理方法如上图。
以下展开介绍各个方法:
## 1 删除法
- **删除观察样本**
将存在缺失数据的样本删除,从而得到一个完备的数据集。这种方法简单易行,在对象有多个属性缺失值、被删除的含缺失值的对象与信息表中的数据量相比非常小的情况下是非常有效的。
> **缺点:**
>- 当缺失数据是**非随机分布**时,这种方法可能导致数据发生偏离,从而导致错误的结果。
> - 造成资源的大量浪费,丢弃了大量隐藏在这些对象中的信息。
>
> **优点:**
> - 操作简单
> - 当缺失值数量较小,并且是**随机分布**时,直接删除影响很小,还能摆脱缺失值的困扰
- **删除变量**
当某个变量缺失值较多,且对研究目标影响不大,可以将变量整体删除。
## 2 插补法
### 2.1 单一插补法
- **均值插补** (均值包括平均值、众数、中位数、或常数(0?)等)
均值插补是在处理数据时可以把变量分为数值型和非数值型,如果是非数值型的缺失数据,运用统计学中众数的原理,用此变量在其他对象中取值频数最多的值来填充缺失值;如果是数值型的缺失值,则取此变量在其他所有对象的取值均值来补齐缺失值。
*Tip:对于正态分布的数据可以使用均值代替,如果数据是倾斜的,使用中位数可能更好。*
- 不过这种方法只能在缺失值是完全随机缺失时为总体均值或总量提供无偏估计。但此方法使得插补值集中在均值点上,在分布上容易形成尖峰,导致方差被低估。
可根据一定的辅助变量,将样本分成多个部分,然后在每一部分上分别使用均值插补,称为局部均值插补。(K-Means、K-NN等)
> **缺点:**
>- 当缺失数据不是随机数据时会产生偏差。(方差)
>- 没有考虑到特征间的相关性
>- 没有考虑到插补值的不确定性
>- 不会非常精确
>
> **优点:**
>- 不会减少样本信息,处理简单,低缺失率首选
----
- **KNN插值**
KNN是一种Classification算法。这种算法基于特征相似性来预测新数据点的值,这就意味着新数据点是基于和其他点的相似程度来被赋值。这对于缺失值的预测非常有用:找到距离缺失值距离最近的K个数据点,然后基于这些点的值来插补缺失值。
- 那它是如何实现的呢?首先创建一个基本的均值插补,使用complete list构建一个KDTree, 然后使用KDTree来计算距离最近的点(NN),找到距离最近的K个点以后,取这些点的加权平均数。
> **优点:**
>- 比mean / median / most frequent插补的方法更精确
>- 易于理解也易于实现
>
>**缺点:**
>- 计算量大,需要在memory里存储整个training数据集
>- 分析大型数据时会很耗时
>- KNN对 outliers 非常敏感
>- 在高维数据集中,最近与最远邻居之间的差别非常小,因此KNN的准确性会降低。
注:**k-means插补**与KNN插补很相似,区别在于k-means是利用无缺失值的特征来寻找最近的N个点,然后用这N个点的我们所需的缺失的特征平均值来填充,而KNN则是先用均值填充缺失值再找最近的N个点。
-----
- **随机插补**
随机插补是在均值插补的基础上加上随机项,通过增加缺失值的随机性来改善缺失值分布过于集中的缺陷,优于纯均值插补。
类似的还有**随机回归插补** :也优于纯回归插补
----
- **期望最大化(EM算法)**
该算法的特点是通过数据扩张,将不完全数据的处理问题转化为对完全数据的处理问题,且通过假设隐变量的存在,简化似然方程,将比较复杂的似然函数极大似然估计问题转化为比较简单的极大似然估计问题。通过以下步骤实现:1、用估计值替代缺失值;2、参数估计;3、假定2中的参数估计值是正确的,再对缺失值进行估计;4、再估计缺失值。
- 该方法比删除个案和单值插补更有吸引力,它一个重要前提:适用于大样本。有效样本的数量足够以保证极大似然估计值是渐近无偏的并服从正态分布。但是这种方法可能会陷入局部极值,收敛速度也不是很快,并且计算很复杂。(SPSS菜单里有这种方法)
> **优点:**
>- 适用于高缺失率 , 适用于大样本
>
> **缺点:**
>- 这种方法可能会陷入局部极值,收敛速度也不是很快,并且计算很复杂。
>- 只有足够多的有效样本才能保证极大似然估计值是渐近无偏的并服从正态分布
-----
**其他单一插补法:**
- 拉格朗日插值填充
(即认为A列数的分布是一个多次多项式,取缺失值前后的N个值,计算出多项式公式然后,带入缺失值进行填充)
- Hot-Deck imputation
从其他相关且相似变量中取值。
------
### 2.2 多重插补法
与单一插补方法相比较,多重插补方法充分地考虑了数据的不确定性。多重插补的主要分为三个步骤,综合起来即为:插补、分析、合并。插补步是为每个缺失值都构造出 m 个可能的插补值,缺失模型具有不确定性,这些插补值能体现出模型的这个性质,利用这些可能插补值对缺失值进行插补就得到了 m 个完整数据集。分析步是对插补后的 m 个完整数据集使用一样的统计数据分析方法进行分析,同时得到 m 个统计结果。综合步就是把得到的这 m 个统计结果综合起来得到的分析结果,把这个分析结果作为缺失值的替代值。多重插补构造多个插补值主要是通过模拟的方式对估计量的分布进行推测,然后采用不同的模型对缺失值进行插补,这种插补是随机抽取的方式,这样以来能提高估计的有效性和可靠性。
[多重插补-python手册](https://blog.csdn.net/qq_41518277/article/details/85101347)
多重插补法主要有以下几种:
- **PMM法**(Predictive Mean Matching,PMM)
PMM法也称随机回归插补法,它是回归插补法的变形,插补值是由回归模型的的预测值加上一个随机产生的误差项结合而成.一般而言,对应于某种确定性的插补方法,可以产生出相应的随机性插补方法.它的优点是能够在正态性假设不成立的情况下插补适当的值,缺点是随机误差项的确定比较困难.
- **趋势得分法**(Propensity Score, PS)
趋势得分是在给定观测协变量时分配给一个特殊处理的条件概率,它对每个有缺失值的变量产生一个趋势得分来表示观测缺失的概率。之后,根据这些趋势得分,把观测分组,最后再对每一组数据应用近似贝叶斯Bootstrap插补。
- **马尔科夫链蒙特卡罗法**(Markov Chain Monte Carlo,MCMC)
MCMC方法是蒙特卡洛重要抽样, 是流行的贝叶斯分析方法中计算后验期望的方法。一般地,MCMC将缺失数据视为参数,然后将这些参数纳入抽样的范围即可。MCMC方法对缺失数据的处理相对灵活、简单易行。
[MCMC—马尔可夫蒙特卡洛抽样](https://zhuanlan.zhihu.com/p/40349550)
[贝叶斯估计、最大似然估计、最大后验概率估计](https://www.jianshu.com/p/9c153d82ba2d)
[有缺失值怎么办——多重填补技术的思路与软件实现](https://mp.weixin.qq.com/s?__biz=MzA5Mjc4NTc0MQ==&mid=2651451387&idx=1&sn=cf75dc1b2713cc064ba3e45a2da22940&chksm=8b9a92d9bced1bcf142e83afc660e0bdb870502b261785b69dbfb515eebdb7235a806b32478b&mpshare=1&scene=23&srcid=0710xoKhNLhmUq2JJWbjeIjf&sharer_sharetime=1594396886159&sharer_shareid=e7aab36d78b279ccf29394736ce26e0f#rd)
> **优点:**
> - 与其他方法相比较,多重插补方法能够尽可能的利用其他辅助信息,给出多个替代值,保持了估计结果的不确定性的大量信息
>- 多重插补方法能够尽可能接近真实情况下去模拟缺失数据的分布,在这样的条件下能够尽可能的保持变量之间的原始关系
>- 在多重插补的插补步骤会产生多个插补值,这样以来就可以利用这些不同的替代值来进一步反映无回答的不确定性。
>
> **缺点:**
>- 生成多重插补比单一插补需要更多工作;
>- 贮存多重插补数据集需要更多存储空间;
>- 分析多重插补数据集比单一插补需要花费更多精力。
> **多重插补(Multiple Imputation,MI)**:多值插补的思想来源于贝叶斯估计,认为待插补的值是随机的,它的值来自于已观测到的值。具体实践上通常是估计出待插补的值,然后再加上不同的噪声,形成多组可选插补值。根据某种选择依据,选取最合适的插补值。
>
>**多重插补方法分为三个步骤**:①为每个空值产生一套可能的插补值,这些值反映了无响应模型的不确定性;每个值都可以被用来插补数据集中的缺失值,产生若干个完整数据集合。②每个插补数据集合都用针对完整数据集的统计方法进行统计分析。③对来自各个插补数据集的结果,根据评分函数进行选择,产生最终的插补值。
>
>假设一组数据,包括三个变量Y1,Y2,Y3,它们的联合分布为正态分布,将这组数据处理成三组,A组保持原始数据,B组仅缺失Y3,C组缺失Y1和Y2。在多值插补时,对A组将不进行任何处理,对B组产生Y3的一组估计值(作Y3关于Y1,Y2的回归),对C组作产生Y1和Y2的一组成对估计值(作Y1,Y2关于Y3的回归)。
>
>当用多值插补时,对A组将不进行处理,对B、C组将完整的样本随机抽取形成为m组(m为可选择的m组插补值),每组个案数只要能够有效估计参数就可以了。**对存在缺失值的属性的分布作出估计**,然后基于这m组观测值,对于这m组样本分别产生关于参数的m组估计值,给出相应的预测即,这时采用的估计方法为极大似然法,在计算机中具体的实现算法为期望最大化法(EM)。对B组估计出一组Y3的值,对C将利用 Y1,Y2,Y3它们的联合分布为正态分布这一前提,估计出一组(Y1,Y2)。
>
>上例中假定了Y1,Y2,Y3的联合分布为正态分布。这个假设是人为的,但是已经通过验证(Graham和Schafer于1999),非正态联合分布的变量,在这个假定下仍然可以估计到很接近真实值的结果。
>
>**多重插补和贝叶斯估计的思想是一致的,但是多重插补弥补了贝叶斯估计的几个不足**
>(1)贝叶斯估计以极大似然的方法估计,极大似然的方法要求模型的形式必须准确,如果参数形式不正确,将得到错误得结论,即先验分布将影响后验分布的准确性。而多重插补所依据的是大样本渐近完整的数据的理论,在数据挖掘中的数据量都很大,先验分布将极小的影响结果,所以先验分布的对结果的影响不大。
>
>(2)贝叶斯估计仅要求知道未知参数的先验分布,没有利用与参数的关系。而多重插补对参数的联合分布作出了估计,利用了参数间的相互关系。
## 3 模型法:
(使用回归、贝叶斯、随机森林、决策树等模型对缺失数据进行预测。)
基于已有的其他字段,将缺失字段作为目标变量进行预测,从而得到较为可能的补全值。如果带有缺失值的列是数值变量,采用回归模型补全;如果是分类变量,则采用分类模型补全。
> 注:
> - 如果其它特征变量与缺失变量无关,则预测的结果毫无意义,会影响最终模型的训练。
> - 而如果预测结果相当准确,则又说明这个变量完全没有必要进行预测,因为这必然是与特征变量间存在重复信息。
> - 一般情况下,会介于两者之间效果为最好,若强行填补缺失值之后引入了自相关,这会给后续分析造成障碍。
## 4 不处理
常见能够自动处理缺失值模型包括:KNN、决策树和随机森林、神经网络和朴素贝叶斯、DBSCAN(基于密度的带有噪声的空间聚类)等。
处理思路:
**自动插补**:例如XGBoost会通过training loss reduction来学习并找到最佳插补值。
**忽略**:缺失值不参与距离计算,例如:KNN,LightGBM
**将缺失值作为分布的一种状态**:并参与到建模过程,例如:决策树以及变体。
**不基于距离做计算**:因此基于值得距离计算本身的影响就消除了,例如:DBSCAN。
> 延伸:**什么样的模型对缺失值更敏感?**
>主流的机器学习模型千千万,很难一概而论。但有一些经验法则(rule of thumb)供参考:
>
>- 树模型对于缺失值的敏感度较低,大部分时候可以在数据有缺失时使用。
>- 涉及到距离度量(distance measurement)时,如计算两个点之间的距离,缺失数据就变得比较重要。因为涉及到“距离”这个概念,那么缺失值处理不当就会导致效果很差,如K近邻算法(KNN)和支持向量机(SVM)。
>- 线性模型的代价函数(loss function)往往涉及到距离(distance)的计算,计算预测值和真实值之间的差别,这容易导致对缺失值敏感。
>- 神经网络的鲁棒性强,对于缺失数据不是非常敏感,但一般没有那么多数据可供使用。
>- 贝叶斯模型对于缺失数据也比较稳定,数据量很小的时候首推贝叶斯模型。
[ID3、c4.5、cart、rf到底是如何处理缺失值的?](https://zhuanlan.zhihu.com/p/84519568)
## 5 映射到高维
最精确的做法,把变量映射到高维空间。
比如性别,有男、女缺失三种情况,则映射成3个变量:是否男、否女、是否缺失。连续型变量也可以这样处理。比如Google、 百度的CTR预估模型,预处理时会把所有变量都这样处理,达到几亿维。又或者可根据每个值的频数,将频数较小的值归为一类'other',降低维度。此做法可最大化保留变量的信息。
> **优点:** 完整保留了原始数据的全部信息不用考虑缺失值、不用考虑线性不可分之类的问题
> **缺点:** 计算量大大提升,而且只有在样本量非常大的时候效果才好,否则会因为过于稀疏,效果很差。
## 6 时间序列分析专属方法
**前推法**(LOCF,Last Observation Carried Forward,将每个缺失值替换为缺失之前的最后一次观测值)与**后推法**(NOCB,Next Observation Carried Backward,与LOCF方向相反——使用缺失值后面的观测值进行填补)
这是分析可能缺少后续观测值的纵向重复测量数据的常用方法。纵向数据在不同时间点跟踪同一样本。当数据具有明显的趋势时,这两种方法都可能在分析中引入偏差,表现不佳。
**线性插值**。此方法适用于具有某些趋势但并非季节性数据的时间序列。
**季节性调整+线性插值**。此方法适用于具有趋势与季节性的数据。
-----
总而言之,大部分数据挖掘的预处理都会使用比较方便的方法来处理缺失值,比如均值法,但是效果上并不一定好,因此还是需要根据不同的需要选择合适的方法,并没有一个解决所有问题的万能方法。
具体的方法采用还需要考虑多个方面的:
- **数据缺失的原因;**
- **数据缺失值类型;**
- **样本的数据量;**
- **数据缺失值随机性等;**
在做数据预处理时,要多尝试几种填充方法,选择表现最佳的即可。
------------------
总结来说,没有一个最完美的策略,每个策略都会更适用于某些数据集和数据类型,但再另一些数据集上表现很差。虽然有一些规则能帮助你决定选用哪一种策略,但除此之外,你还应该尝试不同的方法,来找到最适用于你的数据集的插补策略。
当前最流行的方法应该是 **删除法、KNN、多重插补法**。
---
**一些方法代码可在此查看:** [6种常见处理Missing Value的方法](https://www.dataapplab.com/6-different-ways-to-compensate-for-missing-values-data-imputation-with-examples/)
---
> **总结**:首先查看各特征缺失数量,缺失过多可以直接删除了。而后,使用相关系数查看各特征相关性,以确定各特征的缺失类别,对于强相关的特征可以删除;弱相关的可以使用KNN或者多重插补法;不相关的即为完全随机缺失,可以进一步看看缺失数量考虑使用删除法或者随机均值填充法。当然,除了以上,最好用的还是直接交给模型处理,类似XGboost就业自带处理缺失值的算法。
---
参考文献:[庞新生. 缺失数据处理方法的比较[J]. 统计与决策, 2010(24):152-155.](https://xueshu.baidu.com/usercenter/paper/show?paperid=c70d3e022b34bdf5ece59fe66b7ceb25&site=xueshu_se)