AdaBoost
# 原理
**自适应算法**(AdaBoost)是 Boosting 族算法最著名的代表。
# 核心步骤
AdaBoost 算法的**两个核心步骤**:
1. **每一轮中如何改变训练数据的权值?**
AdaBoost 算法提高那些被前一轮弱分类器错误分类样本的权值,而降低那些被正确分类样本的权值。于是那些没有得到正确分类的数据由于权值的加大而受到后一轮的弱分类器的更大关注。
2. **最后如何将一系列弱分类器组合成一个强分类器?**
>AdaBoost采用**加权多数表决**的方法:
>• 加大分类误差率较小的弱分类器的权值,使得它在表决中起较大作用。
>• 减小分类误差率较大的弱分类器的权值,使得它在表决中起较小的作用。
# 自适应性
AdaBoost 算法具有自适应性,即它能够自动适应弱分类器各自的训练误差率,这也是它的名字(适应的提升)的由来。
# 算法
## 输入与输出
**输入**
- 训练数据集$T=\left\{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \ldots,\left(x_{N}, y_{N}\right)\right\},$ 其中$x_{i} \in \mathcal{X} \subseteq \mathbb{R}^{n}, y_{i} \in \mathcal{Y}=\{-1,+1\}$
- 弱学习器
**输出**
最终分类器 $G(x)$
## 1 初始化训练集的权值分布
::: hljs-center
$D_{1}=\left(w_{11}, \cdots, w_{1 i}, \cdots, w_{1 n}\right), w_{1 i}=\frac{1}{N}, i=1,2, \cdots, N$
:::
## 2 训练模型与更新系数
对于第 m 次训练与系数更新,m=1,2,...,M
**(a) 使用具有权值分布 $D_m$ 的训练数据集学习,得到基本分类器:**
::: hljs-center
$G_{m}(x): \mathcal{X} \rightarrow\{-1,+1\}$
:::
**(b) 计算$G_m(x)$ 在训练集上的(加权分类误差率):**
::: hljs-center
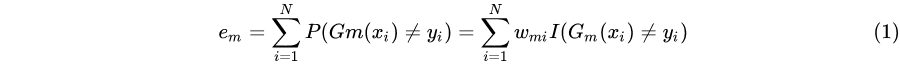
:::
它就是所有误分类点的权重之和。
这里应该有一个判断准则:若$e_{m} \geq \frac{1}{2},$ 算法终止, 构建失败; 当${e}_{m}<\frac{1}{2}$ 时,算法继续。
**(c) 计算 $G_m(x)$ 的系数:**
::: hljs-center
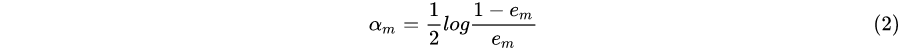
:::
这里的对数是自然对数。
**(d) 更新训练集的权值分布:**
::: hljs-center
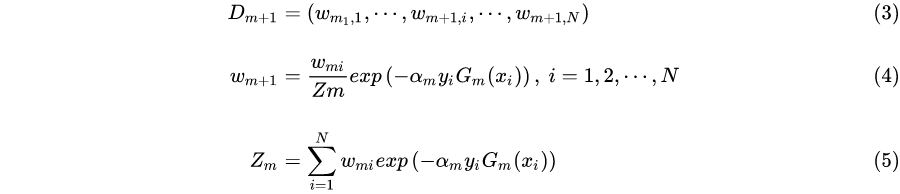
:::
其中,$Z_m$ 是规范化因子,它使 $D_{m+1}$ 成为一个概率分布,即训练集各权值和为 1。
## 3 构建基本分类器的线性组合
::: hljs-center
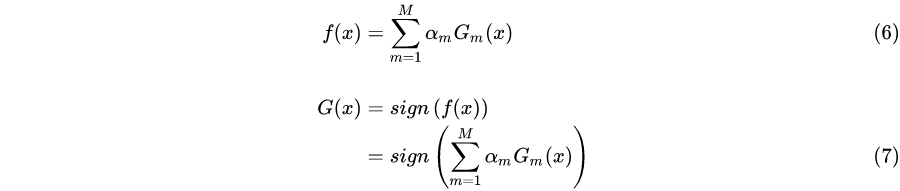
:::
# 算法说明
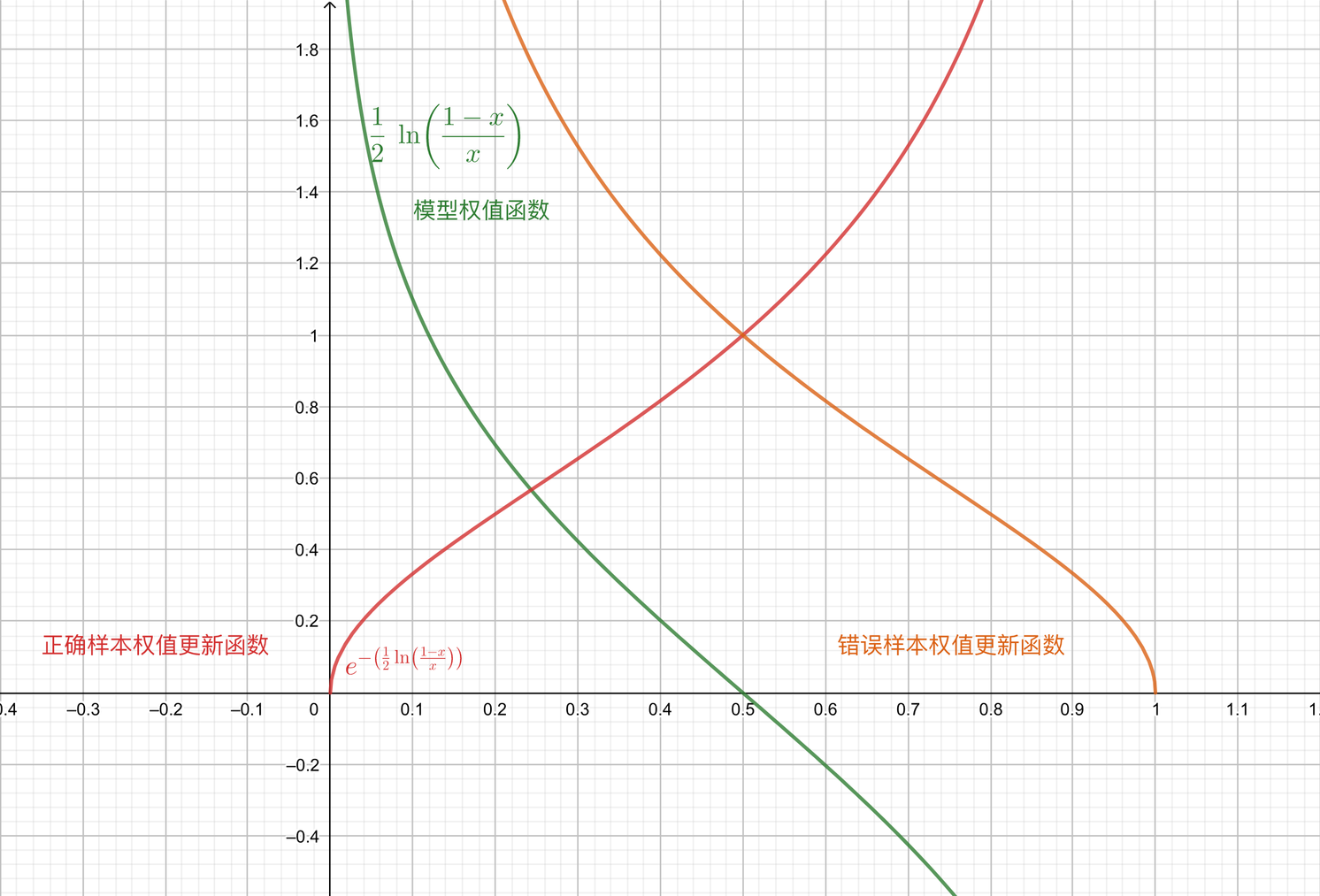
首先给出公式中(2)和(4)的函数图像,其中自变量均为分类误差率 $e_m$:
::: hljs-center
:::
## (1) 分类误差率要求
首先,为什么在(1)中我们要求分类误差率 ${e}_{m}<\frac{1}{2}$ 呢?这是因为:
第一,一个随机分类器的误差率均值即为 1/2,如果一个分类器误差率比 1/2 还大,这就说明这个分类器不仅毫无作用,反而有副作用,这时候一定是基学习器或数据集哪里出问题了,算法停止,重新审视。
第二,从另一个角度,构建的基本分类器的线性组合 $f(x)=\sum_{m=1}^{M} \alpha_{m} G_{m}(x)$ 的系数应该为正,即基本分类器起作用。那么根据(2)公式,即图中的绿色图像可以看出 ${e}_{m}<\frac{1}{2}$。
## (2) 基本分类器权重系数
还是据(2)公式,即图中的绿色图像在 $x<\frac{1}{2}$ 部分,基本分类器的权重系数 $\alpha_m$ 会随着分类误差率 ${e}_{m}$ 的变小而增大,即 ${e}_{m}$ 越小,对应 $G_{m}(x)$ 的权重 $\alpha_m$ 越大。
由于 $\alpha_m$ 是分类误差率 ${e}_{m}$ 的单调递减函数,因此:
- AdaBoost 加大分类误差率较小的弱分类器的权值,使得它在表决中起较大作用。
- AdaBoost 减小分类误差率较大的弱分类器的权值,使得它在表决中起较小的作用。
## (4) 训练集权重更新
对于(4),当 $G_{m}(x)$ 对训练集中的第 $i$ 个样本**预测正确**时:
::: hljs-center
$y_{i} G_{m}\left(x_{i}\right)=1, \exp \left(-\alpha_{m} y_{i} G_{m}\left(x_{i}\right)\right)=\exp \left(-\frac{1}{2} \log \frac{1-e_{m}}{e_{m}}\right)$
:::
即图中红色图像,是 ${e}_{m}$ 的单增函数。由于我们之前就提到过,对于正确分类的样本,下一次学习时其样本权重是要(相对)降低的。但此时,分类错误率 ${e}_{m}$ 越高,模型就不能对正确样本权重降得过低。
当 $G_{m}(x)$ 对训练集中的第 $i$ 个样本**预测错误**时:
::: hljs-center
$y_{i} G_{m}\left(x_{i}\right)=-1, \exp \left(-\alpha_{m} y_{i} G_{m}\left(x_{i}\right)\right)=\exp \left(\frac{1}{2} \log \frac{1-e_{m}}{e_{m}}\right)$
:::
,即图中橙色图像,是 ${e}_{m}$ 的单减函数。对于错误分类的样本,下一次学习时其样本权重是要(相对)提高的。此时,分类错误率 ${e}_{m}$ 越高,模型就不能对错误样本权重定得过高。
两者比较,误分类样本的权重是正确分类样本的权重的 $e^{2 \alpha_{m}}=\frac{1-e_{m}}{e_{m}}$ 倍。于是误分类样本在下一轮学习中权重更大(相对的)。
## (6) 过拟合
为防止过拟合,AdaBoost 通常会加入正则化项。该正则化项称作步长或者学习率,定义为 。考虑正则化项之后,模型的更新方式为:
::: hljs-center
$f_{m}(x)=f_{m-1}(x)+v \cdot \alpha \cdot G_{m}(x)$
:::
# 误差分析
AdaBoost 最基本的性质是它能在学习过程中不断减少训练误差,即在训练数据集上的分类误差率,也就是选取合适 $G_(x)$ 后,随着 $M$ 增大,训练误差$\frac{1}{N} \sum_{i=1}^{N} I\left(G\left(x_{i}\right) \neq y_{i}\right) \leq \exp \left(-2 M \gamma^{2}\right)$
证明以上结论,需要以下几个定理:
**定理1:AdaBoost 的训练误差界**。AdaBoost 算法最终分类器的训练误差界为:
::: hljs-center
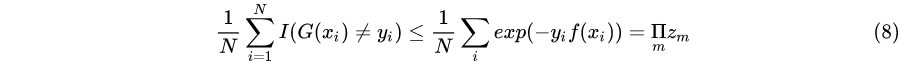
:::
**定理2:二类分类问题 AdaBoost 的训练误差界**
::: hljs-center
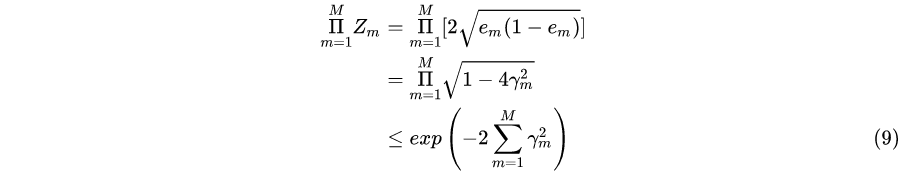
:::
这里,$\gamma_{m}=\frac{1}{2}-e_{m}$
推论1:如果存在 $\gamma>0,$ 对所有 $m$ 有 $\gamma_{m} \geq \gamma,$ 则
::: hljs-center

:::
这表明在此条件下 AdaBoost的训练误差是以指数速率下降的。这一性质当然是很有吸引力的。
注意,AdaBoost 算法不需要知道下届 $\gamma$。与早期的提升方法不同,AdaBoost 具有自适应性,即它能适应弱分类器各自的训练误差率。这也是它的名称的由来。
上述定理都只是关于训练误差的分析,实际应用中更关系测试集的误差。AdaBoost 算法也会出现过拟合,此时训练误差为 0 但是测试集的误差较大。
当 AdaBoost 的基础分类器比较复杂时,AdaBoost 很容易陷入过拟合。但是当 AdaBoost 的基础分类器比较简单时,AdaBoost 反而难以陷入过拟合。这也是为什么 AdaBoost 的基础分类器经常选择使用**树桩**的原因。