其他聚类算法
# 用高斯混合模型(GMM)的最大期望(EM)聚类
K-Means的缺点在于对聚类中心均值的简单使用。下面的图中的两个圆如果使用K-Means则不能作出正确的类的判断。同样的,如果数据集中的点类似下图中曲线的情况也是不能正确分类的。

使用高斯混合模型(GMM)做聚类首先假设数据点是呈高斯分布的,相对应K-Means假设数据点是圆形的,高斯分布(椭圆形)给出了更多的可能性。我们有两个参数来描述簇的形状:均值和标准差。所以这些簇可以采取任何形状的椭圆形,因为在x,y方向上都有标准差。因此,每个高斯分布被分配给单个簇。
所以要做聚类首先应该找到数据集的均值和标准差,我们将采用一个叫做最大期望(EM)的优化算法。下图演示了使用GMMs进行最大期望的聚类过程。
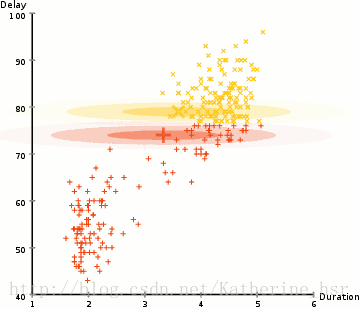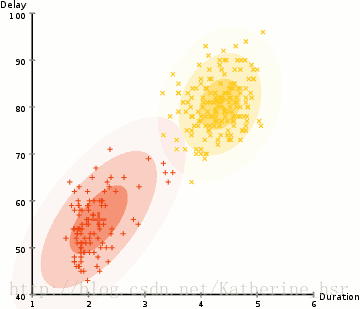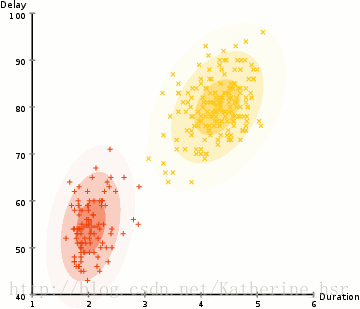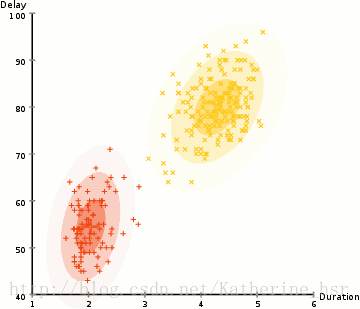
**具体步骤:**
1. 选择簇的数量(与K-Means类似)并随机初始化每个簇的高斯分布参数(均值和方差)。也可以先观察数据给出一个相对精确的均值和方差。
2. 给定每个簇的高斯分布,计算每个数据点属于每个簇的概率。一个点越靠近高斯分布的中心就越可能属于该簇。
3. 基于这些概率我们计算高斯分布参数使得数据点的概率最大化,可以使用数据点概率的加权来计算这些新的参数,权重就是数据点属于该簇的概率。
4. 重复迭代2和3直到在迭代中的变化不大。
**GMMs的优点:**
(1)GMMs使用均值和标准差,簇可以呈现出椭圆形而不是仅仅限制于圆形。K-Means是GMMs的一个特殊情况,是方差在所有维度上都接近于0时簇就会呈现出圆形。
(2)GMMs是使用概率,所以一个数据点可以属于多个簇。例如数据点X可以有百分之20的概率属于A簇,百分之80的概率属于B簇。也就是说GMMs可以支持混合资格。
# 凝聚层次聚类
层次聚类算法分为两类:自上而下和自下而上。凝聚层级聚类(HAC)是自下而上的一种聚类算法。HAC首先将每个数据点视为一个单一的簇,然后计算所有簇之间的距离来合并簇,知道所有的簇聚合成为一个簇为止。
下图为凝聚层级聚类的一个实例:
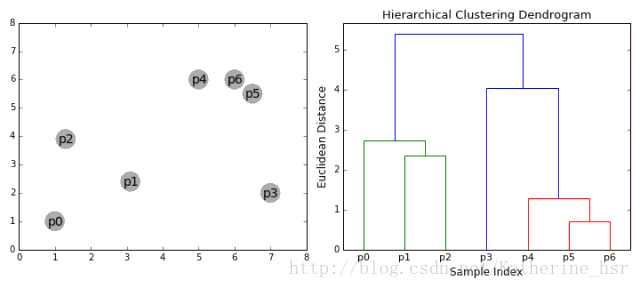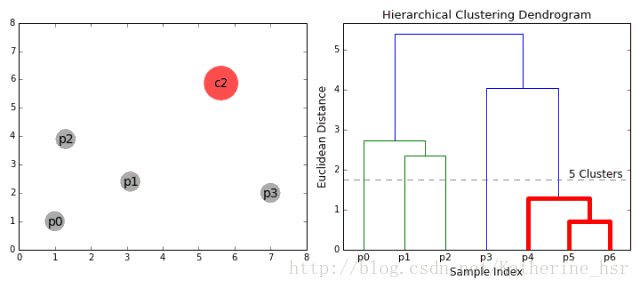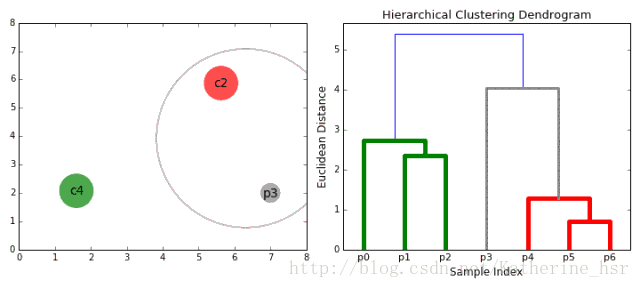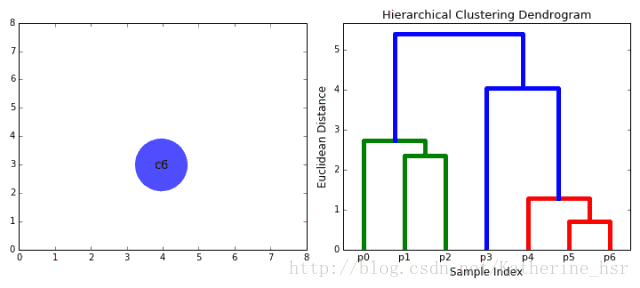
**具体步骤:**
1. 首先我们将每个数据点视为一个单一的簇,然后选择一个测量两个簇之间距离的度量标准。例如我们使用average linkage作为标准,它将两个簇之间的距离定义为第一个簇中的数据点与第二个簇中的数据点之间的平均距离。
2. 在每次迭代中,我们将两个具有最小average linkage的簇合并成为一个簇。
3. 重复步骤2知道所有的数据点合并成一个簇,然后选择我们需要多少个簇。
**层次聚类优点:**
(1)不需要知道有多少个簇
(2)对于距离度量标准的选择并不敏感
**缺点:**
(1)计算复杂度高,不适合数据量大的;
(2)算法很可能形成链状。
# K-modes 和 K-prototypes
K-modes(适用于离散数据,采用汉明距离)
K-prototypes(适用于混合数据(有离散有连续))
> K-prototypes相当于合并了k-means和K-modes,分别计算了数值特征和类别特征的样本距离,然后再对类别特征的距离赋予一个权值gamma,再和数值特征的距离相加,这就是样本间的距离了。问题在于,gamma的确定现在还不明确,原论文也没给出具体的可行方法,而python调用的包里gamma的参数的默认值是none,也就是说算法会用正态分布随机给该参数赋值。我感觉可行的方法是找一个评估聚类函数,然后循环试用多个gamma值。
[聚类方法:K-means、K-modes和K-prototypes](https://blog.csdn.net/qq_38358305/article/details/87775768)
---
转载:[常见的六大聚类算法](https://blog.csdn.net/weixin_42056745/article/details/101287231)