信息增益、信息增益率、基尼指数
# 1、信息增益(ID3算法)
信息增益是特征选择的一个重要指标,它定义为一个特征能够为分类系统带来多少信息,带来的信息越多,说明该特征越重要,**相应的信息增益也就越大**。
## 概念
我们前面说了,**信息熵是代表随机变量的复杂度**(不确定度)[(通俗理解信息熵)](https://zhuanlan.zhihu.com/p/26486223),**条件熵代表在某一个条件下,随机变量的复杂度**(不确定度)[(通俗理解条件熵)](https://zhuanlan.zhihu.com/p/26551798)。
而我们的**信息增益**恰好是:**信息熵-条件熵**。
相应公式如下:
<font size=4>${Gain}(D, a)={Ent}(D)-\sum_{v=1}^{V} \frac{\left|D^{v}\right|}{D} {Ent}\left(D^{v}\right)$</font>
换句话说,信息增益代表了在一个条件下,**信息复杂度(不确定性)减少的程度**。
那么我们现在也很好理解了,在决策树算法中,我们的关键就是每次选择一个特征,特征有多个,那么到底按照什么标准来选择哪一个特征。
这个问题就可以用信息增益来度量。**如果选择一个特征后,信息增益最大**(信息不确定性减少的程度最大),那么我们就选取这个特征。
**例子**
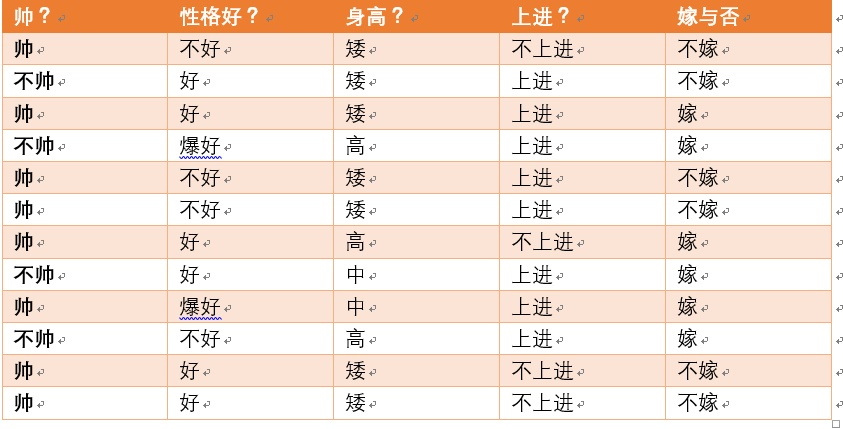
我们有如下数据:
::: hljs-center
:::
可以求得随机变量X(嫁与不嫁)的信息熵为:
嫁的个数为6个,占1/2,那么信息熵为-1/2log1/2-1/2log1/2 = -log1/2=0.301
**现在假如我知道了一个男生的身高信息。**
**身高有三个可能的取值{矮,中,高}**
矮包括{1,2,3,5,6,11,12},嫁的个数为1个,不嫁的个数为6个
中包括{8,9} ,嫁的个数为2个,不嫁的个数为0个
高包括{4,7,10},嫁的个数为3个,不嫁的个数为0个
先回忆一下条件熵的公式如下:
::: hljs-center
<font size=4>$H(Y \mid X)=\sum_{x \in X} p(x) H(Y \mid X=x)$</font>
:::
我们先求出公式对应的:
>H(Y|X = 矮) = -1/7log1/7-6/7log6/7=0.178
>H(Y|X=中) = -1log1-0 = 0
>H(Y|X=高) = -1log1-0=0
>p(X = 矮) = 7/12,p(X =中) = 2/12,p(X=高) = 3/12
**则可以得出条件熵为:**
7/12*0.178+2/12*0+3/12*0 = 0.103
那么我们知道**信息熵与条件熵相减就是我们的信息增益**,为
0.301-0.103=0.198
所以我们可以得出我们在知道了身高这个信息之后,**信息增益是0.198**
## 结论
我们可以知道,本来如果我对一个男生什么都不知道的话,**作为他的女朋友决定是否嫁给他的不确定性有0.301这么大。**
当我们知道男朋友的身高信息后,不确定度减少了0.198.也就是说,**身高这个特征对于我们广大女生同学来说,决定嫁不嫁给自己的男朋友是很重要的。**
至少我们知道了身高特征后,我们原来没有底的心里(0.301)已经明朗一半多了,减少0.198了(大于原来的一半了)。
那么这就类似于非诚勿扰节目里面的桥段了,请问女嘉宾,你只能知道男生的一个特征。请问你想知道哪个特征。
假如其它特征我也全算了,信息增益是身高这个特征最大。那么我就可以说,孟非哥哥,我想知道男嘉宾的一个特征是身高特征。因为它在这些特征中,对于我挑夫君是最重要的,信息增益是最大的,知道了这个特征,嫁与不嫁的不确定度减少的是最多的。
参考:[通俗理解决策树算法中的信息增益](https://zhuanlan.zhihu.com/p/26596036)
# 2、信息增益率(C4.5算法)
为什么要提出信息增益率这种评判划分属性的方法?信息增益不是就很好吗?
其实不然,用信息增益作为评判划分属性的方法其实是有一定的缺陷的,书上说,**信息增益准则对那些属性的取值比较多的属性有所偏好**,也就是说,采用信息增益作为判定方法,会倾向于去选择属性取值比较多的属性。
那么,选择取值多的属性为什么就不好了呢?举个比较极端的例子,如果将身份证号作为一个属性,那么,其实每个人的身份证号都是不相同的,也就是说,有多少个人,就有多少种取值,它的取值很多吧,让我们继续看,如果用身份证号这个属性去划分原数据集D,那么,原数据集D中有多少个样本,就会被划分为多少个子集,每个子集只有一个人,这种极端情况下,因为一个人只可能属于一种类别,好人,或者坏人,那么此时每个子集的信息熵就是0了,就是说此时每个子集都特别纯。这样的话,会导致信息增益公式的第二项$\sum_{v=1}^{V} \frac{\left|D^{v}\right|}{D} {Ent}\left(D^{v}\right)$整体为0,这样导致的结果是,信息增益计算出来的特别大,然后决策树会用身份证号这个属性来划分原数据集D,其实这种划分毫无意义。
因此,为了改变这种不良偏好带来的不利影响,提出了采用信息增益率作为评判划分属性的方法。
公式如下:
::: hljs-center
<font size=4>$Gain\_ratio (D, a)=\frac{{Gain}(D, a)}{I V(a)}$</font>
:::
其中$I V(a)$的计算方式如下:
::: hljs-center
<font size=4>$I V(a)=-\sum_{v=1}^{V} \frac{\left|D^{v}\right|}{D \mid} \log _{2} \frac{\left|D^{v}\right|}{|D|}$</font>
:::
$I V(a)$被称为是的“固有值”,这个$I V(a)$的公式是不是很熟悉啊,简直和信息熵的计算公式一毛一样,就是看属性a的纯度,如果a只含有少量的取值的话,那么a的纯度就比较高,否则的话,a的取值越多,a的纯度越低,$I V(a)$的值也就越大,因此,最后得到的信息增益率就越低。
采用信息增益率可以解决ID3算法中存在的问题(ID3会对那些属性的取值比较多的属性有所偏好,如西瓜的颜色有10种),因此将采用信息增益率作为判定划分属性好坏的方法称为C4.5。
需要注意的是,增益率准则对属性取值较少的时候会有偏好,为了解决这个问题,C4.5并不是直接选择增益率最大的属性作为划分属性,而是之前先通过一遍筛选,先把信息增益低于平均水平的属性剔除掉,之后从剩下的属性中选择信息增益率最高的,这样的话,相当于两方面都得到了兼顾。 (结合信息增益与信息增益率使用)
参考:[信息熵、信息增益与信息增益率](https://blog.csdn.net/qintian888/article/details/90054519)
# 3、基尼指数(CART算法)
基尼系数也是一种衡量信息不确定性的方法,与信息熵计算出来的结果差距很小,基本可以忽略,但是基尼系数要计算快得多,因为没有对数
**定义:** 基尼指数(基尼不纯度):表示在样本集合中一个随机选中的样本被分错的概率。
**注意:** $Gini$指数越小表示集合中被选中的样本被分错的概率越小,也就是说集合的纯度越高,反之,集合越不纯。
即 **基尼指数(基尼不纯度)= 样本被选中的概率 * 样本被分错的概率**
**书中公式:**
::: hljs-center
<font size=4>${Gini}(\mathrm{p})=\sum_{k=1}^{K} p_{k}\left(1-p_{k}\right)=1-\sum_{k=1}^{K} p_{k}{ }^{2}$</font>
:::
**说明:**
>1. $p_k$表示选中的样本属于k类别的概率,则这个样本被分错的概率是$(1-p_k)$
>2. 样本集合中有$k$个类别,一个随机选中的样本可以属于这$k$个类别中的任意一个,因而对类别就加和
>3. 当为二分类是,$Gini(P) = 2p(1-p)$
**样本集合$D$的$Gini$指数 :** 假设集合中有K个类别,则:
::: hljs-center
<font size=4>${Gini}(\mathrm{D})=1-\sum_{k=1}^{K}\left(\frac{\left|C_{k}\right|}{\mid D |}\right)^{2}$</font>
:::
**基于特征A划分样本集合D之后的基尼指数:**
**需要说明**的是CART是个二叉树,也就是当使用某个特征划分样本集合只有两个集合:1. 等于给定的特征值 的样本集合D1,2 不等于给定的特征值 的样本集合D2
实际上是对拥有多个取值的特征的二值处理。
**举个例子:**
假设现在有特征 “学历”,此特征有三个特征取值: “本科”,“硕士”, “博士”,
当使用“学历”这个特征对样本集合D进行划分时,划分值分别有三个,因而有三种划分的可能集合,划分后的子集如下:
>- 划分点: “本科”,划分后的子集合 : {本科},{硕士,博士}
>- 划分点: “硕士”,划分后的子集合 : {硕士},{本科,博士}
>- 划分点: “硕士”,划分后的子集合 : {博士},{本科,硕士}
对于上述的每一种划分,都可以计算出基于 **划分特征= 某个特征值** 将样本集合D划分为两个子集的纯度:
::: hljs-center
<font size=4>${Gini}(\mathrm{D}, \mathrm{A})=\frac{\left|D_{1}\right|}{|D|} {Gini}\left(D_{1}\right)+\frac{\left|D_{2}\right|}{|D|} {Gini}\left(D_{2}\right)$</font>
:::
因而**对于一个具有多个取值(超过2个)的特征,需要计算以每一个取值作为划分点,对样本D划分之后子集的纯度Gini(D,Ai),(其中Ai 表示特征A的可能取值)**
然后从所有的可能划分的Gini(D,Ai)中找出Gini指数最小的划分,这个划分的划分点,便是使用特征A对样本集合D进行划分的最佳划分点。
转载:[决策树--信息增益,信息增益比,Geni指数](https://zhuanlan.zhihu.com/p/84836155)